|
This HTML version of Think Complexity, 2nd Edition is provided for convenience, but it is not the best format of the book. In particular, some of the symbols are not rendered correctly. You might prefer to read the PDF version. Chapter 8 Self-organized criticalityIn the previous chapter we saw an example of a system with a critical point and we explored one of the common properties of critical systems, fractal geometry. In this chapter, we explore two other properties of critical systems: heavy-tailed distributions, which we saw in Chapter ?? and pink noise, which I’ll explain in this chapter. These properties are interesting in part because they appear frequently in nature; that is, many natural systems produce fractal-like geometry, heavy-tailed distributions, and pink noise. This observation raises a natural question: why do so many natural systems have properties of critical systems? A possible answer is self-organized criticality (SOC), which is the tendency of some systems to evolve toward, and stay in, a critical state. In this chapter I’ll present a sand pile model that was the first system shown to exhibit SOC. The code for this chapter is in chap08.ipynb in the repository for this book. More information about working with the code is in Section ??. 8.1 Critical SystemsMany critical systems demonstrate common behaviors:
Critical systems are usually unstable. For example, to keep water in a partially frozen state requires active control of the temperature. If the system is near the critical temperature, a small deviation tends to move the system into one phase or the other. Many natural systems exhibit characteristic behaviors of criticality, but if critical points are unstable, they should not be common in nature. This is the puzzle Bak, Tang and Wiesenfeld address. Their solution is called self-organized criticality (SOC), where “self-organized” means that from any initial condition, the system moves toward a critical state, and stays there, without external control. 8.2 Sand PilesThe sand pile model was proposed by Bak, Tang and Wiesenfeld in 1987. It is not meant to be a realistic model of a sand pile, but rather an abstraction that models physical systems with a large number of elements that interact with their neighbors. The sand pile model is a 2-D cellular automaton where the state of each cell represents the slope of a part of a sand pile. During each time step, each cell is checked to see whether it exceeds a critical value, K, which is usually 3. If so, it “topples” and transfers sand to four neighboring cells; that is, the slope of the cell is decreased by 4, and each of the neighbors is increased by 1. At the perimeter of the grid, all cells are kept at slope 0, so the excess spills over the edge. Bak, Tang and Wiesenfeld initialize all cells at a
level greater than For each perturbation, they measure Most of the time, dropping a single grain causes no cells to topple,
so They conclude that the sand pile model exhibits “self-organized criticality”, which means that it evolves toward a critical state without the need for external control or what they call “fine tuning” of any parameters. And the model stays in a critical state as more grains are added. In the next few sections I replicate their experiments and interpret the results. 8.3 Implementing the Sand PileTo implement the sand pile model, I define a class called
All values in the array are initialized to Here’s the
To show how
Initially,
Now we can select the cells that are above the toppling threshold:
The result is a boolean array, but we can use it as if it were an array of integers like this:
If we correlate this array with the kernel, it makes copies of the
kernel at each location where
And here’s the result:
Notice that where the copies of the kernel overlap, they add up. This array contains the change for each cell, which we use to update the original array:
And here’s the result.
So that’s how With
The return value is a tuple that contains the number of time steps and the total number of cells that toppled. If you are not familiar with Finally, the
Let’s look at a bigger example, with
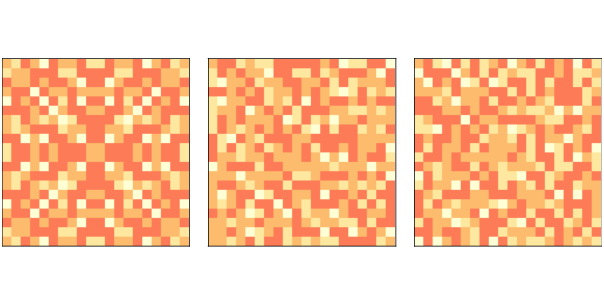
With an initial level of Figure ?? (middle) shows the configuration of the sand pile after dropping 200 grains onto random cells, each time running until the pile reaches equilibrium. The symmetry of the initial configuration has been broken; the configuration looks random. Finally Figure ?? (right) shows the configuration after 400 drops. It looks similar to the configuration after 200 drops. In fact, the pile is now in a steady state where its statistical properties don’t change over time. I’ll explain some of those statistical properties in the next section. 8.4 Heavy-tailed distributionsIf the sand pile model is in a critical state, we expect to find heavy-tailed distributions for quantities like the duration and size of avalanches. So let’s take a look. I’ll make a larger sand pile, with
Next, I’ll run 100,000 random drops
As the name suggests, So
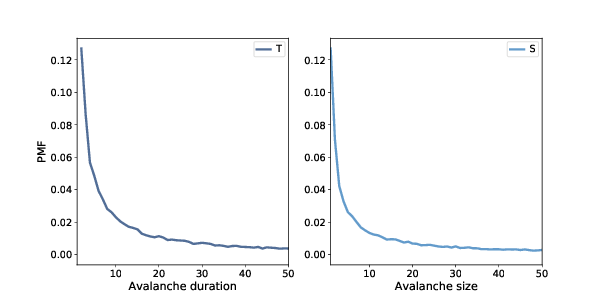
A large majority of drops have duration 1 and no toppled cells; if we filter them out before plotting, we get a clearer view of the rest of the distribution.
The distributions of
Figure ?? shows the results for values less than 50. As we saw in Section ??, we can get a clearer picture of these distributions by plotting them on a log-log scale, as shown in Figure ??. For values between 1 and 100, the distributions are nearly straight on a log-log scale, which is characteristic of a heavy tail. The gray lines in the figure have slopes near -1, which suggests that these distributions follow a power law with parameters near α=1. For values greater than 100, the distributions fall away more quickly than the power law model, which means there are fewer very large values than the model predicts. One possibility is that this effect is due to the finite size of the sand pile; if so, we might expect larger piles to fit the power law better. Another possibility, which you can explore in one of the exercises at the end of this chapter, is that these distributions do not strictly obey a power law. But even if they are not power-law distributions, they might still be heavy-tailed. 8.5 FractalsAnother property of critical systems is fractal geometry. The initial configuration in Figure ?? (left) resembles a fractal, but you can’t always tell by looking. A more reliable way to identify a fractal is to estimate its fractal dimension, as we saw in Section ?? and Section ??. I’ll start by making a bigger sand pile, with
It takes 28,379 steps for this pile to reach equilibrium, with more than 200 million cells toppled. To see the resulting pattern more clearly, I select cells with levels 0, 1, 2, and 3, and plot them separately:
Inside the loop, it uses
Figure ?? shows the results for We’ll count the number of cells in a small box at the center of the pile, then see how the number of cells increases as the box gets bigger. Here’s my implementation:
The parameter, Each time through the loop, The result is a list of tuples, where each tuple contains
Here’s how we use
The first line creates a boolean array that contains The second line unpacks the rows and assigns them to
Figure ?? shows the results. On a log-log scale, the cell counts form nearly straight lines, which indicates that we are measuring fractal dimension over a valid range of box sizes. To estimate the slopes of these lines, we can use the SciPy function
The estimated fractal dimensions are:
The fractal dimension for levels 0, 1, and 2 seems to be clearly non-integer, which indicates that the image is fractal. The estimate for level 3 is indistinguishable from 2, but given the results for the other values, the apparent curvature of the line, and the appearance of the pattern, it seems likely that it is also fractal. One of the exercises in the notebook for this chapter asks you to run
this analysis again with different values of 8.6 Pink noiseThe title of the original paper that presented the sand pile model is “Self-Organized Criticality: An Explanation of 1/f Noise”. You can read it at http://thinkcomplex.com/bak. As the subtitle suggests, Bak, Tang and Wiesenfeld were trying to explain why many natural and engineered systems exhibit 1/f noise, which is also known as “flicker noise” and “pink noise”. To understand pink noise, we have to take a detour to understand signals, power spectrums, and noise.
There are many kinds of noise. For example, “white noise” is a signal that has components with equal power over a wide range of frequencies. Other kinds of noise have different relationships between frequency and power. In “red noise”, the power at frequency f is 1/f2, which we can write like this:
We can generalize this equation by replacing the exponent 2 with a parameter β:
When β=0, this equation describes white noise; when β=2 it describes red noise. When the parameter is near 1, the result is called 1/f noise. More generally, noise with any value between 0 and 2 is called “pink”, because it’s between white and red. We can use this relationship to derive a test for pink noise. Taking the log of both sides yields
So if we plot P(f) versus f on a log-log scale, we expect a straight line with slope −β. What does this have to do with the sand pile model? Suppose that every time a cell topples, it makes a sound. If we record a sand pile model while its running, what would it sound like? In the next section, we’ll simulate the sound of the sand pile model and see if it is pink noise. 8.7 The sound of sandAs my implementation of
To compute the power spectrum of this signal we can use the SciPy function
This function uses Welch’s method, which splits the signal into segments and computes the power spectrum of each segment. The result is typically noisy, so Welch’s method averages across segments to estimate the average power at each frequency. For more about Welch’s method, see http://thinkcomplex.com/welch. The parameter The parameter The return values,
For frequencies between 10 and 1000 (in arbitrary units), the spectrum falls on a straight line, which is what we expect for pink or red noise. The gray line in the figure has slope −1.58, which indicates that
with parameter β=1.58, which is the same parameter reported by Bak, Tang, and Wiesenfeld. This result confirms that the sand pile model generates pink noise. 8.8 Reductionism and HolismThe original paper by Bak, Tang and Wiesenfeld is one of the most frequently-cited papers in the last few decades. Some subsequent papers have reported other systems that are apparently self-organized critical (SOC). Others have studied the sand pile model in more detail. As it turns out, the sand pile model is not a good model of a sand pile. Sand is dense and not very sticky, so momentum has a non-negligible effect on the behavior of avalanches. As a result, there are fewer very large and very small avalanches than the model predicts, and the distribution might not be heavy-tailed. Bak has suggested that this observation misses the point. The sand pile model is not meant to be a realistic model of a sand pile; it is meant to be a simple example of a broad category of models. To understand this point, it is useful to think about two kinds of models, reductionist and holistic. A reductionist model describes a system by describing its parts and their interactions. When a reductionist model is used as an explanation, it depends on an analogy between the components of the model and the components of the system. For example, to explain why the ideal gas law holds, we can model the molecules that make up a gas with point masses and model their interactions as elastic collisions. If you simulate or analyze this model, you find that it obeys the ideal gas law. This model is satisfactory to the degree that molecules in a gas behave like molecules in the model. The analogy is between the parts of the system and the parts of the model. Holistic models are more focused on similarities between systems and less interested in analogous parts. A holistic approach to modeling consists of these steps:
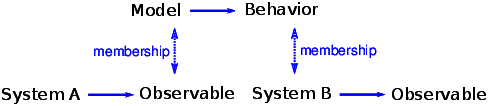
For example, in The Selfish Gene, Richard Dawkins suggests that genetic evolution is just one example of an evolutionary system. He identifies the essential elements of the category — discrete replicators, variability, and differential reproduction — and proposes that any system with these elements will show evidence of evolution. As another example of an evolutionary system, he proposes “memes”, which are thoughts or behaviors that are replicated by transmission from person to person2. As memes compete for the resource of human attention, they evolve in ways that are similar to genetic evolution. Critics of the meme model have pointed out that memes are a poor analogy for genes; they differ from genes in many obvious ways. Dawkins has argued that these differences are beside the point because memes are not supposed to be analogous to genes. Rather, memes and genes are examples of the same category: evolutionary systems. The differences between them emphasize the real point, which is that evolution is a general model that applies to many seemingly disparate systems. The logical structure of this argument is shown in Figure ??. Bak has made a similar argument that self-organized criticality is a general model for a broad category of systems: Since these phenomena appear everywhere, they cannot depend on any specific detail whatsoever... If the physics of a large class of problems is the same, this gives [the theorist] the option of selecting the simplest possible [model] belonging to that class for detailed study.3 Many natural systems demonstrate behaviors characteristic of critical systems. Bak’s explanation for this prevalence is that these systems are examples of the broad category of self-organized criticality. There are two ways to support this argument. One is to build a realistic model of a particular system and show that the model exhibits SOC. The second is to show that SOC is a feature of many diverse models, and to identify the essential characteristics those models have in common. The first approach, which I characterize as reductionist, can explain the behavior of a particular system. The second approach, which I am calling holistic, can explain the prevalence of criticality in natural systems. They are different models with different purposes. For reductionist models, realism is the primary virtue, and simplicity is secondary. For holistic models, it is the other way around. 8.9 SOC, causation, and predictionIf a stock market index drops by a fraction of a percent in a day, there is no need for an explanation. But if it drops 10%, people want to know why. Pundits on television are willing to offer explanations, but the real answer may be that there is no explanation. Day-to-day variability in the stock market shows evidence of criticality: the distribution of value changes is heavy-tailed and the time series exhibits pink noise. If the stock market is a critical system, we should expect occasional large changes as part of the ordinary behavior of the market. The distribution of earthquake sizes is also heavy-tailed, and there are simple models of the dynamics of geological faults that might explain this behavior. If these models are right, they imply that large earthquakes are not exceptional; that is, they do not require explanation any more than small earthquakes do. Similarly, Charles Perrow has suggested that failures in large engineered systems, like nuclear power plants, are like avalanches in the sand pile model. Most failures are small, isolated, and harmless, but occasionally a coincidence of bad fortune yields a catastrophe. When big accidents occur, investigators go looking for the cause, but if Perrow’s “normal accident theory” is correct, there may be no special cause of large failures. These conclusions are not comforting. Among other things, they imply that large earthquakes and some kinds of accidents are fundamentally unpredictable. It is impossible to look at the state of a critical system and say whether a large avalanche is “due”. If the system is in a critical state, then a large avalanche is always possible. It just depends on the next grain of sand. In a sand pile model, what is the cause of a large avalanche? Philosophers sometimes distinguish the proximate cause, which is most immediately responsible, from the ultimate cause, which is considered some deeper kind of explanation (see http://thinkcomplex.com/cause). In the sand pile model, the proximate cause of an avalanche is a grain of sand, but the grain that causes a large avalanche is identical to every other grain, so it offers no special explanation. The ultimate cause of a large avalanche is the structure and dynamics of the systems as a whole: large avalanches occur because they are a property of the system. Many social phenomena, including wars, revolutions, epidemics, inventions, and terrorist attacks, are characterized by heavy-tailed distributions. If these distributions are prevalent because social systems are SOC, major historical events may be fundamentally unpredictable and unexplainable. 8.10 ExercisesThe code for this chapter is in the Jupyter notebook chap08.ipynb in the repository for this book. Open this notebook, read the code, and run the cells. You can use this notebook to work on the following exercises. My solutions are in chap08soln.ipynb. Exercise 1 To test whether the distributions of You might find it helpful to plot the CDFs on a log-x scale and on a log-log scale. Exercise 2 In Section ?? we showed that the initial configuration of the sand pile model produces fractal patterns. But after we drop a large number of random grains, the patterns look more random. Starting with the example in Section ??, run the sand pile model for a while and then compute fractal dimensions for each of the 4 levels. Is the sand pile model fractal in steady state? Exercise 3 Another version of the sand pile model, called the “single source”
model, starts from a different initial condition: instead of all cells
at the same level, all cells are set to 0 except the center cell,
which is set to a large value. Write a function that creates a
You can read more about this version of the sand pile model at http://thinkcomplex.com/sand. Exercise 4 In their 1989 paper, Bak, Chen and Creutz suggest that the Game of Life is a self-organized critical system (see http://thinkcomplex.com/bak89). To replicate their tests, start with a random configuration and run the GoL CA until it stabilizes. Then choose a random cell and flip it. Run the CA until
it stabilizes again, keeping track of Exercise 5 In The Fractal Geometry of Nature, Benoit Mandelbrot proposes what he calls a “heretical” explanation for the prevalence of heavy-tailed distributions in natural systems. It may not be, as Bak suggests, that many systems can generate this behavior in isolation. Instead there may be only a few, but interactions between systems might cause the behavior to propagate. To support this argument, Mandelbrot points out:
What do you think of this argument? Would you characterize it as reductionist or holist? Exercise 6
Read about the “Great Man” theory of history at http://thinkcomplex.com/great. What implication does self-organized criticality have for this theory? |
Buy this book at Amazon.com
ContributeIf you would like to make a contribution to support my books, you can use the button below and pay with PayPal. Thank you!
Are you using one of our books in a class?We'd like to know about it. Please consider filling out this short survey.
|