|
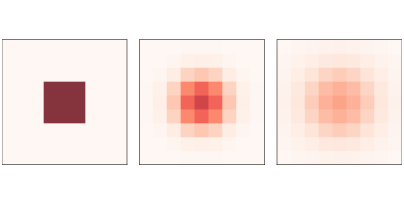
This HTML version of Think Complexity, 2nd Edition is provided for convenience, but it is not the best format of the book. In particular, some of the symbols are not rendered correctly. You might prefer to read the PDF version. Chapter 7 Physical modelingThe cellular automatons we have seen so far are not physical models; that is, they are not intended to describe systems in the real world. But some CAs are intended as physical models. In this chapter we consider a CA that models chemicals that diffuse (spread out) and react with each other, which is a process Alan Turing proposed to explain how some animal patterns develop. And we’ll experiment with a CA that models percolation of liquid through porous material, like water through coffee grounds. This model is the first of several models that exhibit phase change behavior and fractal geometry, and I’ll explain what both of those mean. The code for this chapter is in chap07.ipynb in the repository for this book. More information about working with the code is in Section ??. 7.1 DiffusionIn 1952 Alan Turing published a paper called “The chemical basis of morphogenesis”, which describes the behavior of systems involving two chemicals that diffuse in space and react with each other. He showed that these systems produce a wide range of patterns, depending on the diffusion and reaction rates, and conjectured that systems like this might be an important mechanism in biological growth processes, particularly the development of animal coloration patterns. Turing’s model is based on differential equations, but it can be implemented using a cellular automaton. Before we get to Turing’s model, we’ll start with something simpler: a diffusion system with just one chemical. We’ll use a 2-D CA where the state of each cell is a continuous quantity (usually between 0 and 1) that represents the concentration of the chemical. We’ll model the diffusion process by comparing each cell with the average of its neighbors. If the concentration of the center cell exceeds the neighborhood average, the chemical flows from the center to the neighbors. If the concentration of the center cell is lower, the chemical flows the other way. The following kernel computes the difference between each cell and the average of its neighbors:
Using
We’ll use a diffusion constant,
Figure ?? shows results for a CA with size 7.2 Reaction-diffusionNow let’s add a second chemical. I’ll define a new object,
The radius of the island is one twentieth of Here is the
The parameters are
Now let’s look more closely at the update statements:
The arrays The term The term Finally, the term As long as the rate parameters are not too high, the values of
With different parameters, this model can produce patterns similar to the stripes and spots on a variety of animals. In some cases, the similarity is striking, especially when the feed and kill parameters vary in space. For all simulations in this section, Figure ?? shows results with
Figure ?? shows results with
Figure ?? shows results with Since 1952, observations and experiments have provided some support for Turing’s conjecture. At this point it seems likely, but not yet proven, that many animal patterns are actually formed by reaction-diffusion processes of some kind. 7.3 PercolationPercolation is a process in which a fluid flows through a semi-porous material. Examples include oil in rock formations, water in paper, and hydrogen gas in micropores. Percolation models are also used to study systems that are not literally percolation, including epidemics and networks of electrical resistors. See http://thinkcomplex.com/perc. Percolation models are often represented using random graphs like the ones we saw in Chapter ??, but they can also be represented using cellular automatons. In the next few sections we’ll explore a 2-D CA that simulates percolation. In this model:
If there is a path of wet cells from the top to the bottom row, we say that the CA has a “percolating cluster”. Two questions of interest regarding percolation are (1) the probability that a random array contains a percolating cluster, and (2) how that probability depends on I define a new class to represent a percolation model:
The state of the CA is stored in The state of the top row is set to 5, which represents a wet cell. Using 5, rather than the more obvious 2, makes it possible to use
This kernel defines a 4-cell “von Neumann” neighborhood; unlike the Moore neighborhood we saw in Section ??, it does not include the diagonals. This kernel adds up the states of the neighbors. If any of them are wet, the result will exceed 5. Otherwise the maximum result is 4 (if all neighbors happen to be porous). We can use this logic to write a simple, fast
This function identifies porous cells, where
Figure ?? shows the first few steps of a percolation model
with 7.4 Phase changeNow let’s test whether a random array contains a percolating cluster:
During each time step, it also computes the number of wet cells and
checks whether the number increased since the last step. If not, we
have reached a fixed point without finding a percolating cluster, so
To estimate the probability of a percolating cluster, we generate many random arrays and test them:
When We can estimate the critical value more precisely using a random walk. Starting from an initial value of Here’s the code:
The result is a list of values for The rapid change in behavior near the critical value is called a phase change by analogy with phase changes in physical systems, like the way water changes from liquid to solid at its freezing point. A wide variety of systems display a common set of behaviors and characteristics when they are at or near a critical point. These behaviors are known collectively as critical phenomena. In the next section, we explore one of them: fractal geometry. 7.5 FractalsTo understand fractals, we have to start with dimensions. For simple geometric objects, dimension is defined in terms of scaling behavior. For example, if the side of a square has length l, its area is l2. The exponent, 2, indicates that a square is two-dimensional. Similarly, if the side of a cube has length l, its volume is l3, which indicates that a cube is three-dimensional. More generally, we can estimate the dimension of an object by measuring some kind of size (like area or volume) as a function of some kind of linear measure (like the length of a side). As an example, I’ll estimate the dimension of a 1-D cellular automaton by measuring its area (total number of “on” cells) as a function of the number of rows.
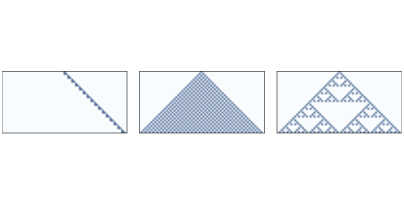
Figure ?? shows three 1-D CAs like the ones we saw in Section ??. Rule 20 (left) generates a set of cells that seems like a line, so we expect it to be one-dimensional. Rule 50 (center) produces something like a triangle, so we expect it to be 2-D. Rule 18 (right) also produces something like a triangle, but the density is not uniform, so its scaling behavior is not obvious. I’ll estimate the dimension of these CAs with the following function, which counts the number of on cells after each time step. It returns a list of tuples, where each tuple contains i, i2, and the total number of cells.
Figure ?? shows the results plotted on a log-log scale. In each figure, the top dashed line shows y = i2. Taking the log of both sides, we have logy = 2 logi. Since the figure is on a log-log scale, the slope of this line is 2. Similarly, the bottom dashed line shows y = i. On a log-log scale, the slope of this line is 1. Rule 20 (left) produces 3 cells every 2 time steps, so the total number of cells after i steps is y = 1.5 i. Taking the log of both sides, we have logy = log1.5 + logi, so on a log-log scale, we expect a line with slope 1. In fact, the estimated slope of the line is 1.01. Rule 50 (center) produces i+1 new cells during the ith time step, so the total number of cells after i steps is y = i2 + i. If we ignore the second term and take the log of both sides, we have logy ∼ 2 logi, so as i gets large, we expect to see a line with slope 2. In fact, the estimated slope is 1.97. Finally, for Rule 18 (right), the estimated slope is about 1.57, which is clearly not 1, 2, or any other integer. This suggests that the pattern generated by Rule 18 has a “fractional dimension”; that is, it is a fractal. This way of estimating a fractal dimension is called box-counting. For more about it, see http://thinkcomplex.com/box. 7.6 Fractals and Percolation Models
Now let’s get back to percolation models. Figure ?? shows
clusters of wet cells in percolation simulations with To estimate their fractal dimension, we can run CAs with a range of sizes, count the number of wet cells in each percolating cluster, and then see how the cell counts scale as we increase the size of the array. The following loop runs the simulations:
The result is a list of tuples where each tuple contains
Figure ?? shows the results for a range of sizes from 10
to 100. The dots show the number of cells in each percolating
cluster. The slope of a line fitted to these dots is often near 1.85,
which suggests that the percolating cluster is, in fact, fractal when
When When 7.7 ExercisesExercise 1 In Section ?? we showed that the Rule 18 CA produces a fractal. Can you find other 1-D CAs that produce fractals? Note: the Exercise 2
In 1990 Bak, Chen and Tang proposed a cellular automaton that is an abstract model of a forest fire. Each cell is in one of three states: empty, occupied by a tree, or on fire. The rules of the CA are:
Write a program that implements this model. You might want to inherit
from Starting from a random initial condition, run the model until it reaches a steady state where the number of trees no longer increases or decreases consistently. In steady state, is the geometry of the forest fractal? What is its fractal dimension? |
Buy this book at Amazon.com
ContributeIf you would like to make a contribution to support my books, you can use the button below and pay with PayPal. Thank you!
Are you using one of our books in a class?We'd like to know about it. Please consider filling out this short survey.
|