|
This HTML version of Think Perl 6 is provided for convenience, but it is not the best format of the book. You might prefer to read the PDF version. Chapter 10 HashesThis chapter presents another built-in type called a hash. Hashes are one of Perl’s best and most commonly used features; they are the building blocks of many efficient and elegant algorithms. 10.1 A Hash is a MappingA hash is like an array, but more general. In an array, the indices or subscripts have to be integers; in a hash, they can be (almost) anything. A hash contains a collection of indices, which are called keys, and a collection of values. Each key is associated with a single value. A key and a value together form a pair (an object of the Pair type), or a key-value pair. A hash can be viewed as a collection of key-value pairs. The values in a hash can also be called items or elements, as with arrays. In other programming languages, hashes are sometimes called dictionaries, hash tables, maps, or associative arrays. In mathematical language, a hash represents a mapping from keys to values, so you can also say that each key “maps to” a value. As an example, we’ll build a hash that maps from English to Spanish words, so the keys and the values are all strings. In Perl, hash names start with the “ > my %eng2sp; This creates an empty hash. To add items to the hash, you can use curly braces (a.k.a. curly brackets and sometimes simply “curlies”): > %eng2sp{'one'} = 'uno';
uno
This line creates an item that maps from the key
If the key is a string containing a single word (i.e., without any space in the middle of it), there is a more idiomatic shortcut to create the same hash entry: > %eng2sp<one> = 'uno'; uno If we print the hash, we see a key-value pair with a
> say %eng2sp; one => uno This output format is also an input format. For example, you can create a new hash with three items: > my %eng2sp = ('one' => 'uno', 'two' => 'dos', 'three' => 'tres');
one => uno, three => tres, two => dos
Using the my %eng2sp = ('one', 'uno', 'two', 'dos', 'three', 'tres');
But the pair constructor has the advantage of showing more graphically the key-value relations. The pair constructor operator also makes the use of quotes non mandatory on its lefthand side (provided the key is a string with no space): > my %eng2sp = (one => 'uno', two => 'dos', three => 'tres'); one => uno, three => tres, two => dos You might also use a more concise list syntax for the hash assignment and Perl will happily convert the list into a hash, provided the number of items in the input list is even: > my %eng2sp = <one uno two dos three tres>; one => uno, three => tres, two => dos You might be surprised by the output. The order of the key-value pairs is usually not the order in which you populated the hash. In general, the order of items in a hash is unpredictable. But that’s not a problem because the elements of a hash are never indexed with integer subscripts. Instead, you use the keys to look up the corresponding values: > say %eng2sp<two>; dos The key If the key isn’t in the hash, you get an undefined value: > say %eng2sp<four>; (Any) The elems method or function works on hashes just as on arrays; it returns the number of key-value pairs: > say %eng2sp.elems; 3 > say elems %eng2sp 3 The :exists adverb also works on hashes as on arrays; it tells you whether something appears as a key in the hash (appearing as a value is not good enough)1: > %eng2sp<two> :exists; True > %eng2sp<four> :exists; False To see whether something appears as a value in a hash, you can use the values method, which returns a collection of values, and then use a loop (or possibly a grep) to look for the searched item: my @vals = values %eng2sp;
for @vals -> $value {
say "Found it!" if $value eq 'uno'; # -> Found it!
}
Or more concisely: say "Found it!" if grep {$_ eq 'uno'}, %eng2sp.values;
Since grep defaults to a smart match, this can be made even more concise: say "Found it!" if grep {'uno'}, %eng2sp.values; # -> Found it!
When looking for values, the program has to search the elements of the list in order (or sequentially), as in Section ??. As the list gets longer, the search time gets longer in direct proportion. By contrast, when looking for keys, Perl uses a hashing algorithm that has a remarkable property: it takes about the same amount of time no matter how many items are in the hash. In other words, it performs really fast, compared to the list size, when the searched list is large. This is the reason why the solution to the reverse pair exercise (Exercise ??) of the previous chapter using a hash was almost three times faster than the bisection search solution (see Subsection ??). As an exercise, use the sample employee data of the multidimensional array of Section ?? (p. ??), load it into a hash, and look up some salaries. Hint: you don’t need a multidimensional structure for doing that with a hash. Solution: ?? 10.2 Common Operations on HashesWe’ve seen already that to populate a hash, you can just assign an even list to it. The four syntactical forms below are correct: my %first_quarter = ("jan" => 1, "feb" => 2, "mar" => 3);
my %second_quarter = (apr => 4, may => 5, jun => 6);
my %third_quarter = jul => 7, aug => 8, sep => 9;
my %fourth_quarter = < oct 10 nov 11 dec 12 >;
To add an element to a hash, just assign the hash with a key: my %months = ("jan" => 1, "feb" => 2, "mar" => 3);
%months{'apr'} = 4;
say %months; # -> apr => 4, feb => 2, jan => 1, mar => 3
Remember that you can also do the same without having to quote the keys if you use the angle brackets quote-word operator (if the keys are strings): %months<apr> = 4; # same as: %months{'apr'} = 4;
or you can also use the push function with a pair: > push %months, (may => 5); apr => 4, feb => 2, jan => 1, mar => 3, may => 5 > my $new-pair = jun => 6 jun => 6 > push %months, $new-pair; apr => 4, feb => 2, jan => 1, jun => 6, mar => 3, may => 5 Using push to add a pair to a hash is not exactly the same, though, as making a hash assignment: if the key already exists, the old value is not replaced by the new one—instead, the old and the new ones are placed into an array (or, if the old value is already an array, then the new value is added to the array): > push %months, (jan => '01');
{apr => 4, feb => 2, jan => [1 01], jun => 6, mar => 3, may => 5}
To check whether a value is defined for a given key, use defined: > say True if defined %months<apr>; True To obtain the number of items in a hash, use the elems method: say %months.elems; # -> 6 To remove a hash item, use the :delete adverb: > push %months, (jud => 7); # Oops, a typo!
apr => 4, feb => 2, jan => 1, jud => 7, jun => 6, mar => 3, may => 5
> %months{'jud'}:delete; # typo now removed
7
> say %months
apr => 4, feb => 2, jan => 1, jun => 6, mar => 3, may => 5
Note that the :delete adverb also returns the value that is being removed.
For example: > for %months.kv -> $key, $val { say "$key => $val" }
jan => 1
apr => 4
mar => 3
jun => 6
may => 5
feb => 2
> say keys %months;
(jan apr mar jun may feb)
> say values %months;
(1 4 3 6 5 2)
> say %months.pairs;
(jan => 1 apr => 4 mar => 3 jun => 6 may => 5 feb => 2)
10.3 Hash as a Collection of CountersSuppose you are given a string and you want to count how many times each letter appears. There are several ways you could do it:
Each of these options performs the same computation, but each of them implements that computation in a different way. An implementation is a way of performing a computation; some implementations are better than others. For example, an advantage of the hash implementation is that we don’t have to know ahead of time which letters appear in the string and we only have to make room for the letters that do appear. Here is what the code might look like: sub histogram (Str $string) {
my %histo;
for $string.comb -> $letter {
%histo{$letter}++;
}
return %histo;
}
The name of the function is histogram, which is a statistical term for a collection of counters (or frequencies). The first line of the
function creates an empty hash. The for loop traverses
the string. Each time through the loop, if the character Here’s how it works: > say histogram("We all live in a yellow submarine")
W => 1, a => 3, b => 1, e => 4, i => 3, l => 5, (...) y => 1
The histogram indicates that the letters 10.4 Looping and HashesIf you use a hash in a for statement, it traverses the pairs of the hash: > for %eng2sp -> $pair { say $pair}
two => dos
three => tres
one => uno
We have named the iteration variable > for %eng2sp -> $pair { say $pair.value ~ " <= " ~ $pair.key; }
dos <= two
tres <= three
uno <= one
Again, the keys are in no particular order. To traverse the keys in sorted order, you can use the keys (plural) and sort functions or methods: my %histo = histogram("We all live in a yellow submarine");
for %histo.keys.sort -> $key {
say "$key\t%histo{$key}";
}
10.5 Reverse LookupGiven a hash But what if you have Here is a function that takes a value and returns the first key that maps to that value: sub reverse-lookup (%hash, $val) {
for %hash -> $pair {
return $pair.key if $pair.value eq $val;
}
return;
}
This subroutine is yet another example of the search pattern.
If we get to the end of the loop, that means Here is an example of a successful reverse lookup: > my %histo = histogram('parrot');
a => 1, o => 1, p => 1, r => 2, t => 1
> my $key = reverse-lookup %histo, "2";
r
And an unsuccessful one: > say reverse_lookup %histo, "3"; Nil Another more concise way to do reverse lookup would be to use grep to retrieve a list of values satisfying our condition: say grep { .value == 2 }, %histo.pairs; # (r => 2)
Another option is to use an expression with the first built-in function to retrieve only the first one: my %histo = histogram('parrot');
say %histo.pairs.first: *.value == 1; # -> p => 1
This latter example uses the “*” whatever parameter which we haven’t covered yet in this book. Let’s just say that, here, the “*” stands successively for every pair of the hash, and the first function returns the first pair that matches the condition on the value (see Section ?? for details on the “*” parameter). A reverse lookup is much slower than a forward lookup; if you have to do it often, or if the hash gets big, the performance of your program will suffer. 10.6 Testing for ExistenceA quite common task is to determine whether something exists or if a given value has already been seen in a program. Using a hash is usually the best solution because finding out whether there is an entry for a given key is very simple and also very efficient: you just need to store the values that you want to watch as a key entry in a hash, and then check for its existence when needed. In such a case, you often don’t really care about the value and you might put basically anything. It is quite common in that case to use “1” as a value, but you might as well store True or any other value you like. Suppose we want to generate 10 random integers between 0 and 49, but want to make sure that the integers are unique. We can use the rand method 10 times on the desired range. But the likelihood to hit twice the same number is far from negligible (see Exercise ?? on the so-called Birthday Paradox and its solution (Subsection ??) for a similar situation). For example, trying this: > my @list; [] > push @list, 50.rand.Int for 1..10; > say @list; [12 25 47 10 19 20 25 42 33 20] produced a duplicate value in the list (25) on the first try. And the second try produced three pairs of duplicates: > say @list; [45 29 29 27 12 27 20 5 28 45] We can use a hash to reject any generated random integer that has already been seen. The following is a possible way to code this: my @list;
my %seen;
while @list.elems < 10 {
my $random = 50.rand.Int;
next if %seen{$random}:exists;
%seen{$random} = 1;
push @list, $random;
}
say @list;
Every valid integer generated is added to both the We have made it step by step and kept two separate data
structures, the my %seen;
while %seen.elems < 10 {
my $random = 50.rand.Int;
push %seen, ($random => 1) unless %seen{$random}:exists;
}
say keys %seen; # -> (39 12 46 27 14 21 4 38 25 47)
This can be further simplified. It is not really necessary here to check whether the generated integer exists in the hash: if it does exist, the old hash element will be replaced by the new one, and the hash will be essentially unchanged. In addition, when evaluated in a scalar numeric context, a hash returns the number of its elements, so that the call to the .elems is not necessary. This is the new version: my %seen;
%seen{50.rand.Int} = 1 while %seen < 10;
say keys %seen; # -> (46 19 5 36 33 1 20 45 47 30)
This last version is probably more concise and more idiomatic, but that’s not meant to say that it is better. It is perfectly fine if you prefer the second or the first version, maybe because you find it clearer. Use whichever version you like better, or your own modified version provided it does the expected work. This is Perl, there is more than one way to do it (TIMTOWTDI). Note however that the pure hash version doesn’t keep the order in which the numbers were generated, so (pseudo)randomness might not be as good. Also note, by the way, that Perl has a pick function or method to choose elements at random from a list without repetition. 10.7 Hash Keys Are UniqueIt is not possible to have the same key in a hash more than once. Trying to map a new value to a key will replace the old value with the new one. Here is an example of hash creation with duplicates keys: > my %friends = (Tom => 5, Bill => 6, Liz => 5, Tom => 7, Jack => 3) Bill => 6, Jack => 3, Liz => 5, Tom => 7 Because two of our friends are named Tom, we lose the data associated with the first of them. This is something you should be careful about: hash keys are unique, so you’ll lose some items if the data associated with your keys has duplicates. The next section will show some ways of dealing with this possible problem. But this key uniqueness property also has very interesting upsides. For example, a typical way of removing duplicates from a list of items is to assign the list items to the keys of a hash (the value does not matter); at the end of the process, the list of keys has no duplicates: > my @array = < a b c d s a z a r e s d z r a >
[a b c d s a z a r e s d z r a]
> my %unique = map { $_ => 1 }, @array;
a => 1, b => 1, c => 1, d => 1, e => 1, r => 1, s => 1, z => 1
> my @unique_array = keys %unique;
[z a e s d c b r]
As you can see, duplicates have been removed from the output
array. In such a simple case, the unique built-in function
would have been sufficient to remove duplicates from
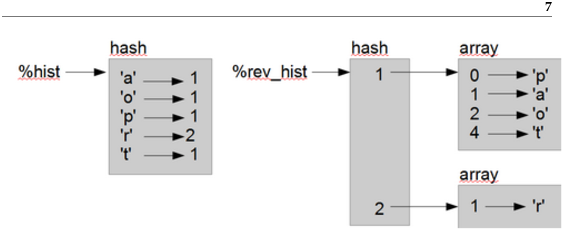
10.8 Hashes and ArraysInverting a hash can be very easy if it is known that the values can happen only once (that they are unique). Consider for example a hash mapping months to their number in the year (we limit the example to five months for brevity): > my %months = jan => 1, feb => 2, mar => 3, apr => 4, may => 5; apr => 4, feb => 2, jan => 1, mar => 3, may => 5 We can transform the key-value pairs into a flat list, reverse the list, and assign the reversed list to a new hash: > my %rev_months = %months.kv.reverse; 1 => jan, 2 => feb, 3 => mar, 4 => apr, 5 => may We now have a new hash mapping month numbers to their names. This can be very handy if a hash is known to be bijective, but this approach does not work correctly if a value can happen more than once: in such a case, some pairs will be lost: > my %months = jan => 1, january => 1, feb => 2, february => 2; feb => 2, february => 2, jan => 1, january => 1 > my %rev_months = %months.kv.reverse; 1 => january, 2 => february Arrays can appear as values in a hash. For example, if you are given a hash that maps from letters to frequencies, you might want to invert it; that is, create a hash that maps from frequencies to letters. Since there might be several letters with the same frequency, each value in the inverted hash should probably be an array of letters. Here is a function that inverts such a hash: sub invert-hash (%in-hash) {
my %out-hash;
for %in-hash.kv -> $key, $val {
push %out-hash{$val}, $key;
}
return %out-hash;
}
Each time through the loop, a hash item is assigned to the Here is an example: my %rev-hist = invert-hash histogram 'parrot'; say %rev-hist; dd %rev-hist; This will display: 1 => [p a o t], 2 => [r]
Hash %rev-hist = {"1" => $["p", "a", "o", "t"], "2" => $["r"]}
Notice that the say function gives a simple representation of the hash data, and that the new dd (short for “data dumper”) function used here gives more detailed information. dd is not very commonly used in normal programs, but can be quite useful while debugging a program to display a detailed description of a complex data structure 2.
say %rev-hist{"1"}[1]; # -> a
Figure ?? is a state diagram showing Arrays can be values in a hash, as this example shows, but they cannot be keys. If you try, you’re likely to end up with a key that contains only one item of the array, but most likely not what you intended: my @a = 'a' .. 'c';
my %h;
%h{@a} = 5;
say %h; # -> a => 5, b => (Any), c => (Any)
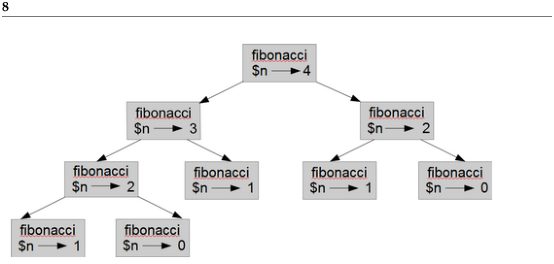
Here, Perl interpreted the As mentioned earlier, a hash is implemented using a hashing function and that means that the keys have to be hashable 3. A hashing is a function that takes a value (of any kind) and returns an integer. Hashes use these integers, called hash values, to store and look up key-value pairs. This system works fine if the keys are immutable. But if the keys are mutable, like with arrays, bad things would happen. For example, when you create a key-value pair, Perl would hash the key and store it in the corresponding location. If you modify the key and then hash it again, it would go to a different location. In that case, you might have two entries for the same key, or you might not be able to find a key. Either way, the hash wouldn’t work correctly. That’s why keys have to be hashable, and why mutable types like arrays aren’t. So Perl will do something else that can be useful (such as creating three distinct hash items in the example above), but will not hash the array itself. Since hashes are mutable, they can’t be used as keys, but they can be used as values, so that you can have nested hashes. 10.9 MemosIf you played with the fibonacci subroutine from Section ??, you might have noticed that the bigger the argument you provide, the longer the subroutine takes to run. Furthermore, the run time increases extremely quickly. To understand why, consider Figure ??, which shows the call graph for fibonacci with n=4.
A call graph shows a set of subroutine frames, with lines
connecting each frame to the frames of the functions it
calls. At the top of the graph, fibonacci with
Count how many times fibonacci(0) and fibonacci(1) are called. This is an inefficient solution to the problem, and it gets much worse as the argument gets bigger. One solution is to keep track of values that have already been computed by storing them in a hash. A previously computed value that is stored for later use is called a memo. Here is a “memoized” version of fibonacci: my %known = 0 => 1, 1 => 1;
say fibonacci(10);
sub fibonacci ($n) {
return %known{$n} if %known{$n}:exists;
%known{$n} = fibonacci($n-1) + fibonacci($n-2);
return %known{$n};
}
Whenever fibonacci is called, it checks If you run this version of fibonacci and compare it with the original, you will find that it is much faster, especially for a large argument (say more than 30). Memoizing is a form of caching, i.e., storing in memory the result of a (presumably costly) computing operation in order to avoid computing it again. This process is sometimes called “trading memory against CPU cycles.” In some cases, such as our Fibonacci recursive example here, the gain can be absolutely huge: calculating the 100th Fibonacci number would take billions of years with the original recursive subroutine and it takes only a split second with the memoized version. Please note that in the specific case of the Fibonacci function, we are storing values for each successive integer; we could have memoized the Fibonacci numbers in an array rather than in a hash (and it might even be slightly more efficient), but using a hash for such purpose is a more general solution, working even when the memo keys are not consecutive integers. As an exercise, try to rewrite the fibonacci subroutine using an array instead of a hash to memoize the calculated Fibonacci numbers. 10.10 Hashes as Dispatch TablesYou may
need a procedure to launch some action depending on the
value of a parameter received by the program. To do that,
you could use a series of
sub run-stop { ... };
sub run-start { ... };
my $param = get-param;
if $param eq "stop" {
run_stop;
} elsif $param eq "start" {
run-start;
} elsif $param = "h" {
say $help;
} elsif $param = "help" {
say $help;
} elsif $param = "v" {
$verbose = True;
} else {
die "Unknown option $param";
}
This approach is boring and error-prone. Using a dispatch table is often a simpler solution. A dispatch table is a data structure mapping identifiers to code references or subroutine objects. Applied to the above scenario, it could look like this: sub run-stop { ... };
sub run-start { ... };
my %dispatch = (
stop => &run-stop,
start => &run-start,
h => { say $help; },
help => { say $help; },
v => { $verbose = True;},
);
my $param = get-param();
die "Unknown option $param" unless %dispatch{$param}:exists;
%dispatch{$param}(); # execute the action specified in %dispatch
The This approach is a bit more concise and slightly cleaner, but there
are some other advantages. It is more maintainable: if you need
to add one option, you just need to add one entry to the hash
and don’t have to add code in the middle of a complicated
chain of nested Another upside is that the dispatch table can be dynamically modified at run time, for example depending on certain external circumstances (for example the day in the month when the program is running) or in accordance with a configuration file. This means that it is possible to dynamically modify the behavior of a program after compile time, while it is already running. This paves the way to some very interesting advanced programming techniques that are beyond the scope of this book. Note that we have been using hashes for our dispatch tables, and this is the most common way to implement them. If it makes sense to have small integers as keys, you could also implement a dispatch table as an array. This is the case, for example, with numbered menu items where the user is prompted to type a number to indicate which menu option to activate. 10.11 Global VariablesIn the memoized Fibonacci example above, the
It is common to use global variables for flags; that is,
boolean variables that indicate (“flag”) whether a condition
is true. For example, some programs use a flag named
my $verbose = True;
sub example1 {
say 'Running example1' if $verbose;
# ...
}
Global variables are also sometimes used for environment variables and parameters passed to the program, as well as for storing a large data structure that is the centerpiece of a program, in order to avoid copying it when passing it around as an argument to subroutines. But, asides from those specific cases, it is usually considered poor practice to use a global variable, because it creates dependencies and unexpected “action-at-a-distance” behaviors between various parts of a program and may lead to difficult-to-track bugs. In the case of our memoized say fibonacci(10);
sub fibonacci ($n) {
state %known = 0 => 1, 1 => 1;
return %known{$n} if %known{$n}:exists;
%known{$n} = fibonacci($n-1) + fibonacci($n-2);
return %known{$n};
}
The 10.12 DebuggingAs you work with bigger datasets it can become unwieldy to debug by printing and checking the output by hand. Here are some suggestions for debugging large data sets:
Again, time you spend building scaffolding can reduce the time you spend debugging. 10.13 Glossary
10.14 ExercisesExercise 1
Write a subroutine that reads the words in words.txt and stores them as keys in a hash. (It doesn’t matter what the values are.) Then you can use the exists adverb as a fast way to check whether a string is in the hash. If you did Exercise ??, you can compare the speed of this implementation with a hash and the bisection search. Solution: ?? Exercise 2
Memoize the Ackermann function from Exercise ??
and see if memoization makes it possible to evaluate the
subroutine with bigger arguments. Hint: no.
Solution: ??.
Exercise 3
If you did Exercise ??, you already have
a function named Use a hash to write a faster, simpler version of
Exercise 4
Two words are “rotate pairs” if you can rotate one of them
and get the other (see Write a program that reads a wordlist (e.g. words.txt and finds all the rotate pairs. Solution: ??. Exercise 5
Here’s another Puzzler from Car Talk (http://www.cartalk.com/content/puzzlers): This was sent in by a fellow named Dan O’Leary. He came upon a common one-syllable, five-letter word recently that has the following unique property. When you remove the first letter, the remaining letters form a homophone of the original word, that is a word that sounds exactly the same. Replace the first letter, that is, put it back and remove the second letter and the result is yet another homophone of the original word. And the question is, what’s the word? You can use the hash from Exercise ?? above to check whether a string is in words.txt. To check whether two words are homophones, you can use the CMU Pronouncing Dictionary. You can download it from http://www.speech.cs.cmu.edu/cgi-bin/cmudict. Write a program that lists all the words in words.txt (or in the CMU dictionary) that solve the Puzzler. Solution: ??.
|
Are you using one of our books in a class?We'd like to know about it. Please consider filling out this short survey.
|