|
This HTML version of Think Perl 6 is provided for convenience, but it is not the best format of the book. You might prefer to read the PDF version. Chapter 7 StringsStrings are not like integers, rationals, and Booleans. A string is a sequence of characters, which means it is an ordered collection of other values, and you sometimes need to access to some of these individual values. In this chapter you’ll see how to analyze, handle, and modify strings, and you’ll learn about some of the methods strings provide. You will also start to learn about a very powerful tool for manipulating text data, regular expressions a.k.a. regexes. 7.1 A String is a SequenceA string is primarily a piece of textual data, but it is technically an ordered sequence of characters. Many programming languages allow you to access individual characters of a string with an index between brackets. This is not directly possible in Perl, but you still can access the characters one at a time using the comb built-in method and the bracket operator: > my $string = "banana"; banana > my $st = $string.comb; (b a n a n a) > say $st[1]; a > say $st[2]; n The comb in the second statement splits the string into a list of characters that you can then access individually with square brackets. The expression in brackets is called an index (it is sometimes also called a subscript). The index indicates which character in the sequence you want (hence the name). But this may not be what you expected: the item with index 1 is the second letter of the word. For computer scientists, the index is usually an offset from the beginning. The offset of the first letter (“b”) is zero, and the offset of the first “a” is 1, not 2, and so on. You could also retrieve a “slice” of several characters in one go using the range operator within the brackets: > say $st[2..5] (n a n a)
Again, the “nana” substring starts on the third letter of
But, even if all this might be useful at times, this is not the way you would usually handle strings in Perl, which has higher level tools that are more powerful and more expressive, so that you seldom need to use indexes or subscripts to access individual characters. Also, if there is a real need to access and manipulate individual letters, it would make more sense to store them in an array, but we haven’t covered arrays yet, so we’ll have to come back to that later. 7.2 Common String OperatorsPerl provides a number of operators and functions to handle strings. Let’s review some of the most popular ones. 7.2.1 String LengthThe first thing we might want to know about a string is its length. The chars built-in returns the number of characters in a string and can be used with either a method or a function syntax: > say "banana".chars; # method invocation syntax 6 > say chars "banana"; # function call syntax 6 Note that, with the advent of Unicode, the notion of string length has become more complicated than it used to be in the era of ASCII-only strings. Today, a character may be made of one, two, or more bytes. The chars routine returns the number of characters (in the sense of Unicode graphemes, which is more or less what humans perceive as characters) within the string, even if some of these characters require an encoding over 2, 3, or 4 bytes. A string with a zero length (i.e., no character) is called an empty string. 7.2.2 Searching For a Substring Within the StringThe index built-in usually takes two arguments, a string and a substring (sometimes called the “haystack” and the “needle”), searches for the substring in the string, and returns the position where the substring is found (or an undefined value if it wasn’t found): > say index "banana", "na"; 2 > say index "banana", "ni"; Nil Here again, the index is an offset from the beginning of the string, so that the index of the first letter (“b”) is zero, and the offset of the first “n” is 2, not 3. You may also call index with a method syntax: > say "banana".index("na");
2
The index function can take a third optional argument, an integer indicating where to start the search (thus ignoring in the search any characters before the start position): > say index "banana", "na", 3; 4 Here, the index function started the search on the middle “a” and thus found the position of the second occurrence of the “na” substring. There is also a rindex function, which searches the string backwards from the end and returns the last position of the substring within the string: > say rindex "banana", "na"; 4 Note that even though the rindex function searches the string backwards (from the end), it returns a position computed from the start of the string. 7.2.3 Extracting a Substring from a StringThe opposite of the index function is the substr function or method, which, given a start position and a length, extracts a substring from a string: > say substr "I have a dream", 0, 6; I have > say "I have a dream".substr(9, 5) dream Note that, just as for the chars function, the length is expressed in characters (or Unicode graphemes), not in bytes. Also, as you can see, spaces separating words within the string obviously count as characters. The length argument is optional; if it is not provided, the substr function returns the substring starting on the start position to the end of the string: > say "I have a dream".substr(7) a dream Similarly, if the length value is too large for the substring starting on the start position, the substr function will also return the substring starting on the start position to the end of the string: > say substr "banana", 2, 10; nana Of course, the start position and length parameters need not be hardcoded numbers as in the examples above; you may use a variable instead (or even an expression or a function returning a numeric value), provided the variable or value can be coerced into an integer. But the start position must be within the string range, failing which you would obtain a Start argument to substr out of range ... error; so you may have to verify it against the length of the string beforehand. You can also start counting backwards from the end of the string with the following syntax: > say "I have a dream".substr(*-5) dream > say substr "I have a dream", *-5; dream Here, the star * may be thought as representing the total size
of the string; 7.2.4 A Few Other Useful String Functions or MethodsThis may not be obvious yet, but we will see soon that the combination of the above string functions gives you already a lot of power to manipulate strings way beyond what you may think possible at this point. Let us just mention very briefly a few additional functions that may prove useful at times. 7.2.4.1 flipThe flip function or method reverses a string: > say flip "banana"; ananab 7.2.4.2 splitThe split function or method splits a string into substrings, based on delimiters found in the string: > say $_ for split "-", "25-12-2016";
25
12
2016
> for "25-12-2016".split("-") -> $val {say $val};
25
12
2016
The delimiter can be a single quoted character as in the examples above or a string of several characters, such as a comma and a space in the example below: > .say for split ", ", "Jan, Feb, Mar"; Jan Feb Mar Remember that By default, the delimiters don’t appear in the output produced by the split function or method, but this behavior can be changed with the use of an appropriate adverb. An adverb is basically a named argument to a function that modifies the way the function behaves. For example, the :v (values) adverb tells split to also output the value of the delimiters: > .perl.say for split ', ', "Jan, Feb, Mar", :v; "Jan" ", " "Feb" ", " "Mar" The other adverbs that can be used in this context are :k (keys), :kv (keys and values), and :p (pairs). Their detailed meaning can be found in the documentation for split (https://docs.perl6.org/routine/split). The skip-empty adverb removes empty chunks from the result list. The split function can also use a regular expression pattern as delimiter, and this can make it much more powerful. We will study regular expressions later in this chapter. 7.2.4.3 String ConcatenationThe > say "ban" ~ "ana"; banana You may chain several occurrences of this operator to concatenate more than two strings: > say "ba" ~ "na" ~ "na"; banana Used as a unary prefix operator,
> say (~42).WHAT; (Str) 7.2.4.4 Splitting on WordsThe words function returns a list of words that make up the string: > say "I have a dream".words.perl;
("I", "have", "a", "dream").Seq
> .say for "I have a dream".words;
I
have
a
dream
7.2.4.5 joinThe join function takes a separator argument and a list of strings as arguments; it interleaves them with the separator, concatenates everything into a single string, and returns the resulting string. This example illustrates the chained use of the words and join functions or methods: say 'I have a dream'.words.join('|'); # -> I|have|a|dream
say join ";", words "I have a dream"; # -> I;have;a;dream
In both cases, words first splits the original string into a list of words, and join stitches the items of this list back into a new string interleaved with the separator. 7.2.4.6 Changing the CaseThe lc and uc routines return respectively a lowercase and an uppercase version of their arguments. There is also a tc function or method returning its argument with the first letter converted to title case (or upper case): say lc "April"; # -> april say "April".lc; # -> april say uc "april"; # -> APRIL say tc "april"; # -> April Remember also that the eq operator checks the equality of two strings. 7.3 String Traversal With a while or for LoopA lot of computations involve processing a string one character at a time. Often they start at the beginning, select each character in turn, do something to it or with it, and continue until the end. This pattern of processing is called a traversal. One way to write a traversal is with a while loop and the index function: my $index = 0;
my $fruit = "banana";
while $index < $fruit.chars {
my $letter = substr $fruit, $index, 1;
say $letter;
$index++;
}
This will output each letter, one at a time: b a n a n a This loop traverses the string and displays each letter on a line by itself. The loop condition is $index < $fruit.chars, so when $index is equal to the length of the string, the condition is false, and the body of the loop doesn’t run. In other words, the loop stops when $index is the length of the string minus one, which corresponds to the last character of the string. As an exercise, write a function that takes a string as an argument and displays the letters backward, one per line. Do it at least once without using the flip function. Solution: ?? Another way to write a traversal is with a for loop: my $fruit = "banana";
for $fruit.comb -> $letter {
say $letter
}
Each time through the loop, the next character in the string is assigned to the variable $letter. The loop continues until no characters are left. The loop could also use the substr function: for 0..$fruit.chars - 1 -> $index {
say substr $fruit, $index, 1;
}
The following example shows how to use concatenation and a for loop to generate an abecedarian series (that is, in alphabetical order). In Robert McCloskey’s book Make Way for Ducklings, the names of the ducklings are Jack, Kack, Lack, Mack, Nack, Ouack, Pack, and Quack. This loop outputs these names in order: my $suffix = 'ack';
for 'J'..'Q' -> $letter {
say $letter ~ $suffix;
}
The output is: Jack Kack Lack Mack Nack Oack Pack Qack Of course, that’s not quite right because “Ouack” and “Quack” are misspelled. As an exercise, modify the program to fix this error. Solution: ??. 7.4 Looping and CountingThe following program counts the number of times the letter “a” appears in a string: my $word = 'banana';
my $count = 0;
for $word.comb -> $letter {
$count++ if $letter eq 'a';
}
say $count; # -> 3
This program demonstrates another pattern of computation called a counter. The variable As an exercise, encapsulate this code in a subroutine named count, and generalize it so that it accepts the string and the searched letter as arguments. Solution: ??. 7.5 Regular Expressions (Regexes)The string functions and methods we have seen so far are quite powerful, and can be used for a number of string manipulation operations. But suppose you want to extract from the string “yellow submarine” any letter that is immediately preceded by the letter “l” and followed by the letter “w”. This kind of “fuzzy search” can be done in a loop, but this is somewhat unpractical. You may try to do it as an exercise if you wish, but you should be warned: it is quite tricky and difficult. Even if you don’t do it, the solution may be of some interest to you: see Subsection??. If you add some further condition, for example that this letter should be extracted or captured (i.e. saved for later use) only if the rest of the string contains the substring “rin”, this starts to be really tedious. Also, any change to the requirements leads to a substantial rewrite or even complete refactoring of the code. For this type of work, regular expressions or regexes are a much more powerful and expressive tool. Here’s one way to extract letters using the criteria described above:: > my $string = "yellow submarine"; yellow submarine > say ~$0 if $string ~~ / l (.) w .*? rin /; o Don’t worry if you don’t understand this example; hopefully it will be clear very soon.
The
The Unless specified otherwise (we will see how later), white space is not significant within a regex pattern. So you can add spaces within a pattern to separate its pieces and make your intentions clearer. Most of the rest of this chapter will cover the basics of constructing such regex patterns and using them. But the concept of regexes is so crucial in Perl that we will also devote a full chapter to this subject and some related matters (Chapter ??). The notion of regular expressions is originally a concept stemming from the theory of formal languages. The first uses of regular expressions in computing came from Unix utilities, some of which still in wide use today, such as grep, created by Ken Thomson in 1973, sed (ca. 1974), and awk, developed a few years later (in 1977) by Aho, Weinberger, and Kernighan. Earlier versions of the Perl language in the 1980s included an extended version of regular expressions, that has since been imitated by many other recent languages. The difference, though, is that regular expressions are deeply rooted within the core of the Perl language, whereas most other languages have adopted them as an add-on or a plug-in, often based or derived on a library known as Perl Compatible Regular Expressions (PCRE). The Perl regular expressions have extended these notions so much that they have little to do with the original language theory concept, so that it has been deemed appropriate to stop calling them regular expressions and to speak about regexes, i.e., a sort of pattern-matching sublanguage that works similarly to regular expressions. 7.6 Using RegexesA simple way to use a regex is to use the smart match operator
say "Matched" if "abcdef" ~~ / bc.e /; # -> Matched Here, the smart match operator compares the “abcdef” string with the /bc.e/ pattern and report a success, since, in this case, the “bc” in the string matches the bc part of the pattern, the dot in the pattern matches any character in the string (and matches in this case d) and, finally, the e of the string matches the e in the pattern.
The part of the string that was matched is contained in the
say ~$/ if "abcdef" ~~ / bc.e /; # -> bcde The matching process might be described as follows (but please note that this is a rough simplification): look in the string (from left to right) for a character matching the first atom (i.e., the first matchable item) of the pattern; when found, see whether the second character can match the second atom of the pattern, and so on. If the entire pattern is used, then the regex is successful. If it fails during the process, start again from the position immediately after the initial match point. (This is called backtracking). And repeat that until one of following occurs:
Let us examine an example of backtracking: say "Matched" if "abcabcdef" ~~ / bc.e /; # -> Matched Here, the regex engine starts by matching “bca” with bc., but that initial match attempt fails, because the next letter in the string, “b,” does not match the “e” of the pattern. The regex engine backtracks and starts the search again from the third letter (“c”) of the string. It starts a new match on the fifth letter of the string (the second “b”), manages to match successfully “bcde,” and exits with a successful status (without even looking for any further match). If the string to be analyzed is contained in the for 'abcdef' { # $_ now contains 'abcdef'
say "Matched" if / cd.f /; # -> Matched
}
You might also use a method invocation syntax: say "Matched" if "abcdef".match(/ b.d.f /); # -> Matched In all cases we have seen so far, we directly used a pattern within a pair of / slash delimiters. We can use other delimiters if we prefix our pattern with the letter “m”: say "Matched" if "abcdef" ~~ m{ bc.e }; # -> Matched
or: say "Matched" if "abcdef" ~~ m! bc.e !; # -> Matched The “m” operator does not alter the way a regex works; it only makes it possible to use delimiters other than slashes. Said differently, the “m” prefix is the standard way to introduce a pattern, but it is implicit and can be omitted when the pattern is delimited with slashes. It is probably best to use slashes, because that’s what people commonly use and recognize immediately, and to use other delimiters only when the regex pattern itself contains slashes. A pattern may also be stored in a variable (or, more accurately, in a regex object), using the rx// operator: my $regex = rx/c..f/; say "Matched" if 'abcdef' ~~ $regex; # -> Matched 7.7 Building your Regex PatternsIt is now time to study the basic building blocks of a regex pattern. 7.7.1 Literal MatchingAs you have probably figured out by now, the simplest case of a regex pattern is a constant string. Matching a string against such a regex is more or less equivalent to searching for that string with the index function: my $string = "superlative";
say "$string contains 'perl'." if $string ~~ /perl/;
# -> superlative contains 'perl'.
Note however that, for such literal matches, the index function discussed earlier is likely to be slightly more efficient than a regex on large strings. The contains method, which returns true if its argument is a substring of its invocant, is also likely to be faster. Alphanumeric characters and the underscore say "Success" if 'name@company.uk' ~~ / name@co /; # Fails to compile say "Success" if 'name@company.uk' ~~ / 'name@co' /; # -> Success say "Success" if 'name@company.uk' ~~ / name\@co/ ; # -> Success say "Success" if 'name@company.uk' ~~ / name '@' co /; # -> Success 7.7.2 Wildcards and Character ClassesRegexes wouldn’t be very useful if they could only do literal matching. We are now getting to the more interesting parts. In a regex pattern, some symbols can match not a specific character, but a whole family of characters, such as letters, digits, etc. They are called character classes. We have already seen that the dot is a sort of wildcard matching any single character of the target string: my $string = "superlative";
say "$string contains 'pe.l'." if $string ~~ / pe . l /;
# -> superlative contains 'pe.l'.
The example above illustrates another feature of regexes: whitespace is usually not significant within regex patterns (unless specified otherwise with the :s or :sigspace adverb, as we will see later). There are predefined character classes of the form say "Matched" if 'abcδ' ~~ / ab\w\w /; # -> Matched Here, the string was matched because, according to the
Unicode standard, Other common character classes include:
say ~$/ if 'Bond 007' ~~ /\w\D\s\d\d\d/; # -> "nd 007" Here, we’ve matched “nd 007”, because we have found one word character (n), followed by a non digit (“d”), followed by a space, followed by three digits. You can also specify your own character classes by inserting
between <[0..9 a..f A..F]> You can negate such a character class by inserting a “-” after
the opening angle bracket. For example, a string is not a
valid hexadecimal integer if it contains any character not
in say "Not an hex number" if $string ~~ /<-[0..9 a..f A..F]>/; Please note that you generally don’t need to escape nonalphanumerical characters in your character classes: say ~$/ if "-17.5" ~~ /(<[\d.-]>+)/; # -> -17.5 In this example, we use the “+” quantifier that we’ll discuss in the next section, but the point here is that you don’t need to escape the dot and the dash within the character class definition. 7.7.3 QuantifiersA quantifier makes a preceding atom1 match not exactly once,
but rather a specified or variable number of times. For
example say ~$/ if 'Bond 007' ~~ /\w\D\s\d\+/; # -> "nd 007" The predefined quantifiers include:
The + and * quantifiers are said to be greedy, which means that they match as many characters as they can. For example: say ~$/ if 'aabaababa' ~~ / .+ b /; # -> aabaabab Here, the say ~$/ if 'aabaababa' ~~ / .+? b /; # -> aab You can also specify a range (min..max) for the number of times an atom may be matched. For example, to match an integer smaller than 1,000: say 'Is a number < 1,000' if $string ~~ / ^ \d ** 1..3 $ /; This matches one to three digits. The For matching an exact number of times, just replace the range with a single number: say 'Is a 3-digit number' if $num ~~ / ^ \d ** 3 $ /; 7.7.4 Anchors and AssertionsSometimes, matching a substring is not good enough; you want to match the whole string, or you want the match to occur at the beginning or at the end of the string, or at some other specific place within the string. Anchors and assertions make it possible to specify where the match should occur. They need to match successfully in order for the whole regex to succeed, but they do not use up characters while matching. 7.7.4.1 AnchorsThe most commonly used anchors are the my $string = "superlative"; say "$string starts with 'perl'" if $string ~~ /^perl/; # (No output) say "$string ends with 'perl'" if $string ~~ /perl$/; # (No output) say "$string equals 'perl'" if $string ~~ /^perl$/; # (No output) All three regexes above fail because, even though
In the event that you are handling multiline strings, you might
also use the There are some other useful anchors, such as the 7.7.4.2 Look-Around AssertionsLook-around assertions make it possible to specify more complex rules: for example, match “foo”, but only if preceded (or followed) by “bar” (or not preceded or not followed by “bar”): say "foobar" ~~ /foo <?before bar>/; # -> foo (lookahead assertion) say "foobaz" ~~ /foo <?before bar>/; # -> Nil (regex failed) say "foobar" ~~ /<?after foo> bar/; # -> bar (lookbehind assertion) Using an exclamation mark instead of a question mark transforms these look-around assertion into negative assertions. For example: say "foobar" ~~ /foo <!before baz>/; # -> foo say "foobaz" ~~ /foo <!before baz>/; # -> Nil (regex failed) say "foobar" ~~ /<!after foo> bar/; # -> Nil (regex failed) I assume that the examples above are rather clear. Look into the documentation (https://docs.perl6.org/language/regexes#Look-around_assertions) if you need further details. 7.7.4.3 Code AssertionsYou can also include a code assertion > say ~$/ if /\d\d <?{$/ == 42}>/ for <A12 B34 C42 D50>;
42
A negative code assertion > say ~$/ if /\d\d <!{$/ == 42}>/ for <A12 B34 C42 D50>
12
34
50
Code assertions are useful to specify conditions that cannot easily be expressed as regexes. They can also be used to display something, for example for the purpose of debugging a regex by printing out information about partial matches: > say "Matched $/" if "A12B34D50" ~~ /(\D) <?{ say ~$0}> \d\d$/;
A
B
D
Matched D50
The output shows the various attempted matches that failed (“A” and “B”) before the backtracking process ultimately led to success (“D50” at the end of the string). However, code assertions are in fact rarely needed for such simple cases, because you can very often just add a simple code block for the same purpose: > say "Matched $/" if "A12B34D50" ~~ /(\D) { say ~$0} \d\d$/;
This code produces the same output, and there is no need to worry about whether the block returns a true value. 7.7.5 AlternationAlternations are used to match one of several alternatives. For example, to check whether a string represents one of the three base image colors (in JPEG and some other image formats), you might use: say 'Is a JPEG color' if $string ~~ /^ [ red | green | blue ] $/;
There are two forms of alternations. First-match alternation
uses the say ~$/ if "abcdef" ~~ /ab || abcde/; # -> ab Here, the pattern matches “ab”, without trying to match any further, although there would be an arguably “better” (i.e., longer) match with the other alternative. When using this type of alternation, you have to think carefully about the order in which you put the various alternatives, depending on what you need to do.
The longest-match alternation uses the say ~$/ if "abcdef" ~~ /ab | abcde/; # -> abcde Beware, though, that this will work as explained only if the alternative matches all start on the same position within the string: say ~$/ if "abcdef" ~~ /ab | bcde/; # -> ab Here, the match on the leftmost position wins (this is a general rule with regexes). 7.7.6 Grouping and CapturingParentheses and square brackets can be used to group things together or to override precedence: / a || bc / # matches 'a' or 'bc' / ( a || b ) c / # matches 'ac' or 'bc' / [ a || b ] c / # Same: matches 'ac' or 'bc', non-capturing grouping / a b+ / # Matches an 'a' followed by one or more 'b's / (a b)+ / # Matches one or more sequences of 'ab' / [a b]+ / # Matches one or more sequences of 'ab', non-capturing / (a || b)+ / # Matches a sequence of 'a's and 'b's(at least one) The difference between parentheses and square brackets is that parentheses don’t just group things together, they also capture data: they make the string matched within the parentheses available as a special variable (and also as an element of the resulting match object): my $str = 'number 42'; say "The number is $0" if $str ~~ /number\s+ (\d+) /; # -> The number is 42
Here, the pattern matched the say "$0 $1 $2" if "abcde" ~~ /(a) b (c) d (e)/; # -> a c e # or: say "$/[0..2]" if "abcde" ~~ /(a) b (c) d (e)/; # -> a c e The As noted, the parentheses perform two roles in regexes:
they group regex elements and they capture what is matched
by the subregex within parentheses. If you want only the
grouping behavior, use square brackets
say ~$0 if 'cacbcd' ~~ / [a||b] (c.) /; # -> cb Using square brackets when there is no need to capture
text has the advantage of not cluttering the 7.7.7 Adverbs (a.k.a. Modifiers)Adverbs modify the way the regex engine works. They often have a long form and a shorthand form. For example, the > say so 'AB' ~~ /ab/; False > say so 'AB' ~~ /:i ab/; True
The If placed before the pattern, an adverb applies to the whole pattern: > say so 'AB' ~~ m:i/ ab/; True The adverb may also be placed later in the pattern and affects in this case only the part of the regex that comes afterwards: > say so 'AB' ~~ /a :i b/; False > say so 'aB' ~~ /a :i b/; True
I said earlier that whitespace is usually not significant
in regex patterns. The > say so 'ab' ~~ /a+ b/; True > say so 'ab' ~~ /:s a+ b/; False > say so 'ab' ~~ /:s a+b/; True Instead of searching for just one match and returning a
match object, the > say "Word count = ", $/.elems if "I have a dream" ~~ m:g/ \w+/; Word count = 4 > say ~$/[3]; dream
These are the most commonly used adverbs. Another adverb,
7.7.8 Exercises on RegexesAs a simple exercise, write some regexes to match and capture:
Solution: ?? 7.8 Putting It All TogetherThis section is intended to give a few examples using several of the regex features we have seen for solving practical problems together. 7.8.1 Extracting DatesAssume we have a string containing somewhere a date in the YYYY-MM-DD format: my $string = "Christmas : 2016-12-25."; As mentioned earlier, one of the mottos in Perl is “There is more than one way to do it” (TIMTOWTDI). The various examples below should illustrate that principle quite well by showing several different ways to retrieve the date in the string:
The $string ~~ /(\d ** 4) \- (\d\d) \- (\d\d)/; say $/.prematch; # -> "Christmas : " say $/.postmatch; # -> "." As an exercise, try to adapt the above regexes for various
other date formats (such as DD/MM/YYYY or
YYYY MM, DD) and test them. If you’re trying with
the YYYY MM, DD format, please remember that spaces are
usually not significant in a regex pattern, so you may need
either to specify explicit spaces (using for example the 7.8.2 Extracting an IP AddressAssume we have a string containing an IP-v4 address somewhere. IP addresses are most often written in the dot-decimal notation, which consists of four octets of the address expressed individually in decimal numbers and separated by periods, for example 17.125.246.28. For the purpose of these examples, our sample target string will be as follows: my $string = "IP address: 17.125.246.28;"; Let’s now try a few different ways to capture the IP address in that string, in the same way as we just did for the dates:
7.9 SubstitutionsReplacing part of a string with some other substring is a very frequent requirement in string handling. This might be needed for spelling corrections, data reformatting, removal of personal information from data, etc. 7.9.1 The subst MethodPerl has a subst method which can replace some text with some other text: my $string = "abcdefg";
$string = $string.subst("cd", "DC"); # -> abDCefg
The first argument to this method is the search part, and can be a literal string, as in the example above, or a regex: my $string = "abcdefg"; $string = $string.subst(/c \w+ f/, "SUBST"); # -> abSUBSTg 7.9.2 The s/search/replace/ ConstructThe most common way to perform text substitution
in Perl is the This is an example of the standard syntax for this type of substitution: my $string = "abcdefg"; $string ~~ s/ c \w+ f /SUBST/; # -> abSUBSTg Here, the search part is a regex and the replacement part is a simple string (no quotation marks needed). If the input string is contained in the $_ = "abcdefg"; s/c \w+ f/SUBST/; # -> abSUBSTg The delimiters don’t need to be slashes (and this can be quite useful if either the search or the replacement contain slashes): my $str = "<c>foo</c> <a>foo</a>"; $str ~~ s!'<a>foo</a>'!<a>bar</a>!; # -> <c>foo</c> <a>bar</a> Unless specified otherwise (with an adverb), the substitution is done only once, which helps to prevent unexpected results: $_ = 'There can be twly two'; s/tw/on/; # Replace 'tw' with 'on' once .say; # There can be only two If the substitution were done throughout the string, “two” would have been replaced by “ono”, clearly not the expected result. 7.9.3 Using CapturesIf the regex on the lefthand side contains captures, the
replacement part on the righthand side can use the my $string = "Xmas = 2016-12-25";
$string ~~ s/(\d ** 4) \- (\d\d) \- (\d\d)/$2-$1-$0/;
# $string is now: Xmas = 25-12-2016
7.9.4 AdverbsThe adverbs discussed above (Section ??) can be used with the substitution operator. The modifiers most commonly used in substitutions are the :ignorecase (or :i) and :global (or :g) adverbs. They work just as described in Subsection ?? of the section on regexes and matching. The one specific point to be made here is that substitutions are usually done only once. But with the :global (or :g) adverb, they will be done throughout the whole string: my $string = "foo bar bar foo bar"; $string ~~ s:g/bar/baz/; # string is now "foo baz baz foo baz" 7.10 DebuggingWhen you use indices to traverse the values in a sequence, it is tricky to get the beginning and end of the traversal right. Here is a subroutine that is supposed to compare two words and return True if one of the words is the reverse of the other, but it contains two errors: # ATTENTION, watch out: code with errors
sub is-reverse(Str $word1, Str $word2) {
return False if $word1.chars != $word2.chars;
my $i = 0;
my $j = $word2.chars;
while $j > 0 {
return False if substr($word1, $i, 1) ne substr($word1, $j, 1);
$i++; $j--;
}
return True;
}
say is-reverse "pots", "stop";
The first postfix if statement checks whether the words are the same length. If not, we can return False immediately. Otherwise, for the rest of the subroutine, we can assume that the words are the same length. This is an example of the guardian pattern described in Section ?? (p. ??). $i and $j are indices: $i traverses $word1 forward while $j traverses $word2 backward. If we find two letters that don’t match, we can return False immediately. If we get through the whole loop and all the letters match, we return True. If we test this function with the words “stop” and “pots”, we expect the return value True, but we get False instead. So, what’s wrong here? With this kind of code, the usual suspect is a possible blunder in the management of indices (especially perhaps an off-by-one error). For debugging this kind of error, the first move might be to print the values of the indices immediately before the line where they are used: sub is-reverse(Str $word1, Str $word2) {
return False if $word1.chars != $word2.chars;
my $i = 0;
my $j = $word2.chars;
while $j > 0 {
say '$i = ', $i, ' $j = ', $j;
return False if substr($word1, $i, 1) ne substr($word1, $j, 1);
$i++; $j--;
}
return True;
}
Now when we run the program again, we get more information: $i = 0 $j = 4 False The first time through the loop, the value of $j is 4,
which is out of range for the string Note that in the event that this was still not enough for us to spot the out-or-range error, we could have gone one step further and printed the letters themselves, and we would have seen that we did not get the last letter of the second word. If we fix that error and run the program again, we get: $i = 0 $j = 3 $i = 1 $j = 2 $i = 2 $j = 1 True This time we get the right answer, but it looks like the loop only ran three times, which is suspicious: it seems that the program did not compare the last letter of the first word (indexed $i = 3) with the last letter of the second word (indexed $j = 0). We can confirm this by running the subroutine with the following arguments: “stop” and “lots”, which displays: $i = 0 $j = 3 $i = 1 $j = 2 $i = 2 $j = 1 True This is obviously wrong, “lots” is not the reverse of “stop”, the subroutine should return False. So we have another bug here. To get a better idea of what is
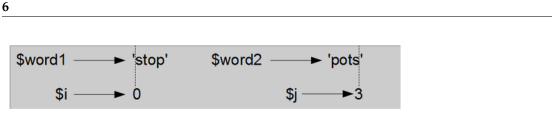
happening, it is useful to draw a state diagram. During the first
iteration, the frame for
We took some license by arranging the variables in the frame and adding dotted lines to show that the values of $i and $j indicate characters in $word1 and $word2. Starting with this diagram, run the program on paper, changing the values of $i and $j during each iteration. Find and fix the second error in this function. Solution: ??. 7.11 Glossary
7.12 ExercisesExercise 1
Write a subroutine that uses the index function in a
loop to count the number of “a” characters in Write another subroutine counting a given letter in a given word using the substr function. Solution: ?? Exercise 2
The [fontshape=up]
sub is-lower (Str $char) {
return so $char ~~ /^<[a..z]>$/
}
should return True if its argument is an ASCII lower case letter and False otherwise. Test that it works as expected (and amend it if needed). The so function coerces the result of the regex match into a Boolean value. The following subroutines use the is-lower subroutine and are all intended to check whether a string contains any lowercase letters, but at least some of them are wrong. Analyze each subroutine by hand, determine whether it is correct, and describe what it actually does (assuming that the parameter is a string). Then test them with various input strings to check whether your analysis was correct. [fontshape=up]
# ATTENTION: some of the subroutines below are wrong
sub any_lowercase1(Str $string){
for $string.comb -> $char {
if is-lower $char {
return True;
} else {
return False;
}
}
}
sub any_lowercase2(Str $string){
for $string.comb -> $char {
if is-lower "char" {
return True;
} else {
return False;
}
}
}
sub any_lowercase3(Str $string){
my $flag;
for $string.comb -> $char {
$flag = is-lower $char;
}
return $flag;
}
sub any_lowercase4(Str $string){
my $flag = False;
for $string.comb -> $char {
$flag = $flag or is-lower $char;
}
return $flag;
}
sub any_lowercase5(Str $string){
my $flag = False;
for $string.comb -> $char {
if is-lower $char {
$flag = True;
}
}
return $flag;
}
sub any_lowercase6(Str $string){
for $string.comb -> $char {
if is-lower $char {
return 'True';
}
}
return 'False';
}
sub any_lowercase7(Str $string){
for $string.comb -> $char {
return True if is-lower $char;
}
return False;
}
sub any_lowercase8(Str $string){
for $string.comb -> $char {
return False unless is-lower $char;
}
return True;
}
sub any_lowercase9(Str $string){
for $string.comb -> $char {
if not is-lower $char {
return False;
}
return True;
}
}
Solution: ??. Exercise 3
A Caesar cipher is a weak form of encryption that involves “rotating” each letter by a fixed number of places. To rotate a letter means to shift it through the alphabet, wrapping around to the beginning if necessary, so “A” rotated by 3 is “D” and “Z” rotated by 1 is “A.” To rotate a word, rotate each letter by the same amount. For example, “cheer” rotated by 7 is “jolly” and “melon” rotated by -10 is “cubed.” In the movie 2001: A Space Odyssey, the ship computer is called HAL, which is IBM rotated by -1. Write a function called You might want to use the built-in functions ord, which converts a character to a numeric code (Unicode code point), and chr, which converts such numeric codes back to characters: [fontshape=up] > say 'c'.ord; 99 > say chr 99 c Letters of the alphabet are encoded in alphabetical order, so for example: [fontshape=up]
> ord('c') - ord('a')
2
because Potentially offensive jokes on the internet are sometimes encoded in ROT13, which is a Caesar cipher with rotation 13. Since 13 is half the number of letters in our alphabet, applying rotation 13 twice returns the original word, so that the same procedure can be used for both encoding and decoding in rotation 13. If you are not easily offended, find and decode some of these jokes. (ROT13 is also used for other purposes, such as weakly hiding the solution to a puzzle.) Solution: ??.
|
Are you using one of our books in a class?We'd like to know about it. Please consider filling out this short survey.
|