|
This HTML version of Think Complexity, 2nd Edition is provided for convenience, but it is not the best format of the book. In particular, some of the symbols are not rendered correctly. You might prefer to read the PDF version. Chapter 5 Cellular AutomatonsA cellular automaton (CA) is a model of a world with very simple physics. “Cellular” means that the world is divided into discrete chunks, called cells. An “automaton” is a machine that performs computations — it could be a real machine, but more often the “machine” is a mathematical abstraction or a computer simulation. This chapter presents experiments Stephen Wolfram performed in the 1980s, showing that some cellular automatons display surprisingly complicated behavior, including the ability to perform arbitrary computations. I discuss implications of these results, and at the end of the chapter I suggest methods for implementing CAs efficiently in Python. The code for this chapter is in chap05.ipynb in the repository for this book. More information about working with the code is in Section ??. 5.1 A simple CACellular automatons1 are governed by rules that determine how the state of the cells changes over time. As a trivial example, consider a cellular automaton (CA) with a single cell. The state of the cell during time step i is an integer, xi. As an initial condition, suppose x0 = 0. Now all we need is a rule. Arbitrarily, I’ll pick xi+1 = xi + 1, which says that during each time step, the state of the CA gets incremented by 1. So this CA performs a simple calculation: it counts. But this CA is atypical; normally the number of possible states is finite. As an example, suppose a cell can only have one of two states, 0 or 1. For a 2-state CA, we could write a rule like xi+1 = (xi + 1) % 2, where % is the remainder (or modulus) operator. The behavior of this CA is simple: it blinks. That is, the state of the cell switches between 0 and 1 during each time step. Most CAs are deterministic, which means that rules do not have any random elements; given the same initial state, they always produce the same result. But some CAs are nondeterministic; we will see examples later. The CA in this section has only one cell, so we can think of it as zero-dimensional. In the rest of this chapter, we explore one-dimensional (1-D) CAs; in the next chapter we explore two-dimensional CAs. 5.2 Wolfram’s experimentIn the early 1980s Stephen Wolfram published a series of papers presenting a systematic study of 1-D CAs. He identified four categories of behavior, each more interesting than the last. You can read one of these papers, “Statistical mechanics of cellular automata," at http://thinkcomplex.com/ca. In Wolfram’s experiments, the cells are arranged in a lattice (which you might remember from Section ??) where each cell is connected to two neighbors. The lattice can be finite, infinite, or arranged in a ring. The rules that determine how the system evolves in time are based on the notion of a “neighborhood”, which is the set of cells that determines the next state of a given cell. Wolfram’s experiments use a 3-cell neighborhood: the cell itself and its two neighbors. In these experiments, the cells have two states, denoted 0 and 1 or “off" and “on". A rule can be summarized by a table that maps from the state of the neighborhood (a tuple of three states) to the next state of the center cell. The following table shows an example:
The first row shows the eight states a neighborhood can be in. The second row shows the state of the center cell during the next time step. As a concise encoding of this table, Wolfram suggested reading the bottom row as a binary number; because 00110010 in binary is 50 in decimal, Wolfram calls this CA “Rule 50”.
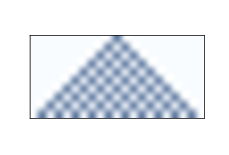
Figure ?? shows the effect of Rule 50 over 10 time steps. The first row shows the state of the system during the first time step; it starts with one cell “on” and the rest “off”. The second row shows the state of the system during the next time step, and so on. The triangular shape in the figure is typical of these CAs; is it a consequence of the shape of the neighborhood. In one time step, each cell influences the state of one neighbor in either direction. During the next time step, that influence can propagate one more cell in each direction. So each cell in the past has a “triangle of influence” that includes all of the cells that can be affected by it. 5.3 Classifying CAs
How many of these CAs are there? Since each cell is either on or off, we can specify the state of a cell with a single bit. In a neighborhood with three cells, there are 8 possible configurations, so there are 8 entries in the rule tables. And since each entry contains a single bit, we can specify a table using 8 bits. With 8 bits, we can specify 256 different rules. One of Wolfram’s first experiments with CAs was to test all 256 possibilities and classify them. Examining the results visually, he proposed that the behavior of CAs can be grouped into four classes. Class 1 contains the simplest (and least interesting) CAs, the ones that evolve from almost any starting condition to the same uniform pattern. As a trivial example, Rule 0 always generates an empty pattern after one time step. Rule 50 is an example of Class 2. It generates a simple pattern with nested structure, that is, a pattern that contains many smaller versions of itself. Rule 18 makes the nested structure is even clearer; Figure ?? shows what it looks like after 64 steps. This pattern resembles the Sierpiński triangle, which you can read about at http://thinkcomplex.com/sier. Some Class 2 CAs generate patterns that are intricate and pretty, but compared to Classes 3 and 4, they are relatively simple. 5.4 Randomness
Class 3 contains CAs that generate randomness. Rule 30 is an example; Figure ?? shows what it looks like after 100 time steps. Along the left side there is an apparent pattern, and on the right side there are triangles in various sizes, but the center seems quite random. In fact, if you take the center column and treat it as a sequence of bits, it is hard to distinguish from a truly random sequence. It passes many of the statistical tests people use to test whether a sequence of bits is random. Programs that produce random-seeming numbers are called pseudo-random number generators (PRNGs). They are not considered truly random because:
Modern PRNGs produce sequences that are statistically indistinguishable from random, and they can be implemented with periods so long that the universe will collapse before they repeat. The existence of these generators raises the question of whether there is any real difference between a good quality pseudo-random sequence and a sequence generated by a “truly” random process. In A New Kind of Science, Wolfram argues that there is not (pages 315–326). 5.5 DeterminismThe existence of Class 3 CAs is surprising. To explain how surprising, let me start with philosophical determinism (see http://thinkcomplex.com/deter). Many philosophical stances are hard to define precisely because they come in a variety of flavors. I often find it useful to define them with a list of statements ordered from weak to strong:
My goal in constructing this range is to make D1 so weak that virtually everyone would accept it, D4 so strong that almost no one would accept it, with intermediate statements that some people accept. The center of mass of world opinion swings along this range in response to historical developments and scientific discoveries. Prior to the scientific revolution, many people regarded the working of the universe as fundamentally unpredictable or controlled by supernatural forces. After the triumphs of Newtonian mechanics, some optimists came to believe something like D4; for example, in 1814 Pierre-Simon Laplace wrote: We may regard the present state of the universe as the effect of its past and the cause of its future. An intellect which at a certain moment would know all forces that set nature in motion, and all positions of all items of which nature is composed, if this intellect were also vast enough to submit these data to analysis, it would embrace in a single formula the movements of the greatest bodies of the universe and those of the tiniest atom; for such an intellect nothing would be uncertain and the future just like the past would be present before its eyes. This “intellect” is now called “Laplace’s Demon”. See http://thinkcomplex.com/demon. The word “demon” in this context has the sense of “spirit”, with no implication of evil. Discoveries in the 19th and 20th centuries gradually dismantled Laplace’s hope. Thermodynamics, radioactivity, and quantum mechanics posed successive challenges to strong forms of determinism. In the 1960s chaos theory showed that in some deterministic systems prediction is only possible over short time scales, limited by precision in the measurement of initial conditions. Most of these systems are continuous in space (if not time) and nonlinear, so the complexity of their behavior is not entirely surprising. Wolfram’s demonstration of complex behavior in simple cellular automatons is more surprising — and disturbing, at least to a deterministic world view. So far I have focused on scientific challenges to determinism, but the longest-standing objection is the apparent conflict between determinism and human free will. Complexity science provides a possible resolution of this conflict; I’ll come back to this topic in Section ??. 5.6 Spaceships
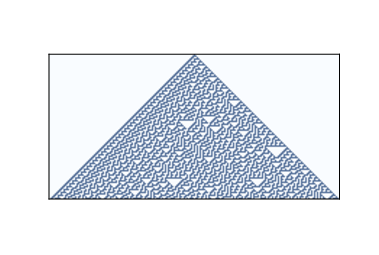
The behavior of Class 4 CAs is even more surprising. Several 1-D CAs, most notably Rule 110, are Turing complete, which means that they can compute any computable function. This property, also called universality, was proved by Matthew Cook in 1998. See http://thinkcomplex.com/r110. Figure ?? shows what Rule 110 looks like with an initial condition of a single cell and 100 time steps. At this time scale it is not apparent that anything special is going on. There are some regular patterns but also some features that are hard to characterize. Figure ?? shows a bigger picture, starting with a random initial condition and 600 time steps:
After about 100 steps the background settles into a simple repeating pattern, but there are a number of persistent structures that appear as disturbances in the background. Some of these structures are stable, so they appear as vertical lines. Others translate in space, appearing as diagonals with different slopes, depending on how many time steps they take to shift by one column. These structures are called spaceships. Collisions between spaceships yield different results depending on the types of the spaceships and the phase they are in when they collide. Some collisions annihilate both ships; others leave one ship unchanged; still others yield one or more ships of different types. These collisions are the basis of computation in a Rule 110 CA. If you think of spaceships as signals that propagate through space, and collisions as gates that compute logical operations like AND and OR, you can see what it means for a CA to perform a computation. 5.7 UniversalityTo understand universality, we have to understand computability theory, which is about models of computation and what they compute. One of the most general models of computation is the Turing machine, which is an abstract computer proposed by Alan Turing in 1936. A Turing machine is a 1-D CA, infinite in both directions, augmented with a read-write head. At any time, the head is positioned over a single cell. It can read the state of that cell (usually there are only two states) and it can write a new value into the cell. In addition, the machine has a register, which records the state of the machine (one of a finite number of states), and a table of rules. For each machine state and cell state, the table specifies an action. Actions include modifying the cell the head is over and moving one cell to the left or right. A Turing machine is not a practical design for a computer, but it models common computer architectures. For a given program running on a real computer, it is possible (at least in principle) to construct a Turing machine that performs an equivalent computation. The Turing machine is useful because it is possible to characterize the set of functions that can be computed by a Turing machine, which is what Turing did. Functions in this set are called “Turing computable". To say that a Turing machine can compute any Turing-computable function is a tautology: it is true by definition. But Turing-computability is more interesting than that. It turns out that just about every reasonable model of computation anyone has come up with is “Turing complete"; that is, it can compute exactly the same set of functions as the Turing machine. Some of these models, like lamdba calculus, are very different from a Turing machine, so their equivalence is surprising. This observation led to the Church-Turing Thesis, which is the claim that these definitions of computability capture something essential that is independent of any particular model of computation. The Rule 110 CA is yet another model of computation, and remarkable for its simplicity. That it, too, turns out to be Turing complete lends support to the Church-Turing Thesis. In A New Kind of Science, Wolfram states a variation of this thesis, which he calls the “principle of computational equivalence” (see http://thinkcomplex.com/equiv): Almost all processes that are not obviously simple can be viewed as computations of equivalent sophistication. Applying these definitions to CAs, Classes 1 and 2 are “obviously simple”. It may be less obvious that Class 3 is simple, but in a way perfect randomness is as simple as perfect order; complexity happens in between. So Wolfram’s claim is that Class 4 behavior is common in the natural world, and that almost all systems that manifest it are computationally equivalent. 5.8 FalsifiabilityWolfram holds that his principle is a stronger claim than the Church-Turing thesis because it is about the natural world rather than abstract models of computation. But saying that natural processes “can be viewed as computations” strikes me as a statement about theory choice more than a hypothesis about the natural world. Also, with qualifications like “almost” and undefined terms like “obviously simple”, his hypothesis may be unfalsifiable. Falsifiability is an idea from the philosophy of science, proposed by Karl Popper as a demarcation between scientific hypotheses and pseudoscience. A hypothesis is falsifiable if there is an experiment, at least in the realm of practicality, that would contradict the hypothesis if it were false. For example, the claim that all life on earth is descended from a common ancestor is falsifiable because it makes specific predictions about similarities in the genetics of modern species (among other things). If we discovered a new species whose DNA was almost entirely different from ours, that would contradict (or at least bring into question) the theory of universal common descent. On the other hand, “special creation”, the claim that all species were created in their current form by a supernatural agent, is unfalsifiable because there is nothing that we could observe about the natural world that would contradict it. Any outcome of any experiment could be attributed to the will of the creator. Unfalsifiable hypotheses can be appealing because they are impossible to refute. If your goal is never to be proved wrong, you should choose hypotheses that are as unfalsifiable as possible. But if your goal is to make reliable predictions about the world — and this is at least one of the goals of science — unfalsifiable hypotheses are useless. The problem is that they have no consequences (if they had consequences, they would be falsifiable). For example, if the theory of special creation were true, what good would it do me to know it? It wouldn’t tell me anything about the creator except that he has an “inordinate fondness for beetles” (attributed to J. B. S. Haldane). And unlike the theory of common descent, which informs many areas of science and bioengineering, it would be of no use for understanding the world or acting in it. 5.9 What is this a model of?
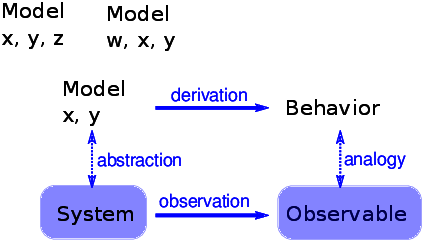
Some cellular automatons are primarily mathematical artifacts. They are interesting because they are surprising, or useful, or pretty, or because they provide tools for creating new mathematics (like the Church-Turing thesis). But it is not clear that they are models of physical systems. And if they are, they are highly abstracted, which is to say that they are not very detailed or realistic. For example, some species of cone snail produce a pattern on their shells that resembles the patterns generated by cellular automatons (see http://thinkcomplex.com/cone). So it is natural to suppose that a CA is a model of the mechanism that produces patterns on shells as they grow. But, at least initially, it is not clear how the elements of the model (so-called cells, communication between neighbors, rules) correspond to the elements of a growing snail (real cells, chemical signals, protein interaction networks). For conventional physical models, being realistic is a virtue. If the elements of a model correspond to the elements of a physical system, there is an obvious analogy between the model and the system. In general, we expect a model that is more realistic to make better predictions and to provide more believable explanations. Of course, this is only true up to a point. Models that are more detailed are harder to work with, and usually less amenable to analysis. At some point, a model becomes so complex that it is easier to experiment with the system. At the other extreme, simple models can be compelling exactly because they are simple. Simple models offer a different kind of explanation than detailed models. With a detailed model, the argument goes something like this: “We are interested in physical system S, so we construct a detailed model, M, and show by analysis and simulation that M exhibits a behavior, B, that is similar (qualitatively or quantitatively) to an observation of the real system, O. So why does O happen? Because S is similar to M, and B is similar to O, and we can prove that M leads to B.” With simple models we can’t claim that S is similar to M, because it isn’t. Instead, the argument goes like this: “There is a set of models that share a common set of features. Any model that has these features exhibits behavior B. If we make an observation, O, that resembles B, one way to explain it is to show that the system, S, has the set of features sufficient to produce B.” For this kind of argument, adding more features doesn’t help. Making the model more realistic doesn’t make the model more reliable; it only obscures the difference between the essential features that cause B and the incidental features that are particular to S. Figure ?? shows the logical structure of this kind of model. The features x and y are sufficient to produce the behavior. Adding more detail, like features w and z, might make the model more realistic, but that realism adds no explanatory power. 5.10 Implementing CAsTo generate the figures in this chapter, I wrote a Python class called
To store the state of the CA, I use a NumPy array with one column for each cell and one row for each time step. To explain how my implementation works, I’ll start with a CA that computes the parity of the cells in each neighborhood. The “parity” of a number is 0 if the number is even and 1 if it is odd. I use the NumPy function
The data type
I import
To compute the state of the CA during time step
Each time through the loop, we select three elements from In this example, the lattice is finite, so the first and last cells have only one neighbor. To handle this special case, I don’t update the first and last column; they are always 0. 5.11 Cross-correlationThe operation in the previous section — selecting elements
from an array and adding them up — is an example of an operation that is so useful, in so many domains, that it has a name: cross-correlation.
And NumPy provides a function, called The NumPy
We can write this operation in Python like this:
This function computes element
And a window:
With this window, each element,
We can use
Here’s the result:
The NumPy function
The argument The drawback of this mode is that the result is not the same size as
Now the result is the same size as We can use NumPy’s implementation of
In the notebook for this chapter, you’ll see that 5.12 CA tablesThe function we have so far works if the CA is “totalitic", which means that the rules only depend on the sum of the neighbors. But most rules also depend on which neighbors are on and off. For example, We can make Here’s the more general version of
The first two lines are the same. Then the last line looks
up each element from Here’s the function that computes the table:
The parameter,
The code in this section is encapsulated in the 5.13 ExercisesThe code for this chapter is in the Jupyter notebook chap05.ipynb in the repository for this book. Open this notebook, read the code, and run the cells. You can use this notebook to work on the exercises in this chapter. My solutions are in chap05soln.ipynb. Exercise 1
Write a version of correlate that returns the same result as np.correlate with mode='same'. Hint: use the NumPy function pad.
Exercise 2 This exercise asks you to experiment with Rule 110 and some of its spaceships.
Exercise 3 The goal of this exercise is to implement a Turing machine.
Exercise 4 This exercise asks you to implement and test several PRNGs.
For testing, you will need to install
Exercise 5
Falsifiability is an appealing and useful idea, but among philosophers of science it is not generally accepted as a solution to the demarcation problem, as Popper claimed. Read http://thinkcomplex.com/false and answer the following questions.
|
Buy this book at Amazon.com
ContributeIf you would like to make a contribution to support my books, you can use the button below and pay with PayPal. Thank you!
Are you using one of our books in a class?We'd like to know about it. Please consider filling out this short survey.
|