|
This HTML version of Think Complexity, 2nd Edition is provided for convenience, but it is not the best format of the book. In particular, some of the symbols are not rendered correctly. You might prefer to read the PDF version. Chapter 12 Evolution of cooperationIn this final chapter, I take on two questions, one from biology and one from philosophy:
The tools I use to address these questions are agent-based simulation (again) and game theory, which is a set of abstract models meant to describe ways agents interact. Specifically, the game we will consider is the Prisoner’s Dilemma. The code for this chapter is in 12.1 Prisoner’s DilemmaThe Prisoner’s Dilemma is a topic in game theory, but it’s not the fun kind of game. Instead, it is the kind of game that sheds light on human motivation and behavior. Here is the presentation of the dilemma from Wikipedia (http://thinkcomplex.com/pd): Two members of a criminal gang are arrested and imprisoned. Each prisoner is in solitary confinement with no means of communicating with the other. The prosecutors lack sufficient evidence to convict the pair on the principal charge, but they have enough to convict both on a lesser charge. Simultaneously, the prosecutors offer each prisoner a bargain. Each prisoner is given the opportunity to either: (1) betray the other by testifying that the other committed the crime, or (2) cooperate with the other by remaining silent. The offer is: Obviously, this scenario is contrived, but it is meant to represent a variety of interactions where agents have to choose whether to “cooperate" with each other or “defect", and where the reward (or punishment) for each agent depends on what the other chooses. With this set of punishments, it is tempting to say that the players should cooperate, that is, that both should remain silent. But neither agent knows what the other will do, so each has to consider two possible outcomes. First, looking at it from A’s point of view:
No matter what B does, A is better off defecting. And because the game is symmetric, this analysis is the same from B’s point of view: no matter what A does, B is better off defecting. In the simplest version of this game, we assume that A and B have no other considerations to take into account. They can’t communicate with each other, so they can’t negotiate, make promises, or threaten each other. And they consider only the immediate goal of minimizing their sentences; they don’t take into account any other factors. Under those assumptions, the rational choice for both agents is to defect. That might be a good thing, at least for purposes of criminal justice. But for the prisoners, it is frustrating because there is, apparently, nothing they can do to achieve the outcome they both want. And this model applies to other scenarios in real life where cooperation would be better for the greater good as well as for the players. Studying these scenarios, and ways to escape from the dilemma, is the focus of people who study game theory, but it is not the focus of this chapter. We are headed in a different direction. 12.2 The problem of niceSince the Prisoner’s Dilemma was first discussed in the 1950s, it has been a popular topic of study in social psychology. Based on the analysis in the previous section, we can say what a perfectly rational agent should do; it is harder to predict what real people actually do. Fortunately, the experiment has been done1. If we assume that people are smart enough to do the analysis (or understand it when explained), and that they generally act in their own interest, we would expect them to defect pretty much all the time. But they don’t. In most experiments, subjects cooperate much more than the rational agent model predicts2. The most obvious explanation of this result is that people are not rational agents, which should not be a surprise to anyone. But why not? Is it because they are not smart enough to understand the scenario or because they are knowingly acting contrary to their own interest? Based on experimental results, it seems that at least part of the explanation is plain altruism: many people are willing to incur a cost to themselves in order to benefit another person. Now, before you nominate that conclusion for publication in the Journal of Obvious Results, let’s keep asking why:
This apparent contradiction is the “problem of altruism": why haven’t the genes for altruism died out? Among biologists, there are many possible explanations, including reciprocal altruism, sexual selection, kin selection, and group selection. Among non-scientists, there are even more explanations. I leave it to you to explore the alternatives; for now I want to focus on just one explanation, arguably the simplest one: maybe altruism is adaptive. In other words, maybe genes for altruism make people more likely to survive and reproduce. It turns out that the Prisoner’s Dilemma, which raises the problem of altruism, might also help resolve it. 12.3 Prisoner’s dilemma tournamentsIn the late 1970s Robert Axelrod, a political scientist at the University of Michigan, organized a tournament to compare strategies for playing Prisoner’s Dilemma (PD). He invited participants to submit strategies in the form of computer programs, then played the programs against each other and kept score. Specifically, they played the iterated version of PD, in which the agents play multiple rounds against the same opponent, so their decisions can be based on history. In Axelrod’s tournaments, a simple strategy that did surprisingly well was called “tit for tat", or TFT. TFT always cooperates during the first round of an iterated match; after that, it copies whatever the opponent did during the previous round. If the opponent keeps cooperating, TFT keeps cooperating. If the opponent defects at any point, TFT defects in the next round. But if the opponent goes back to cooperating, so does TFT. For more information about these tournaments, and an explanation of why TFT does so well, see this video: http://thinkcomplex.com/pdvid2. Looking at the strategies that did well in these tournaments, Alexrod identified the characteristics they tended to share:
TFT has all of these properties. Axelrod’s tournaments offer a partial, possible answer to the problem of altruism: maybe the genes for altruism are prevalent because they are adaptive. To the degree that many social interactions can be modeled as variations on the Prisoner’s Dilemma, a brain that is wired to be nice, tempered by a balance of retaliation and forgiveness, will tend to do well in a wide variety of circumstances. But the strategies in Axelrod’s tournaments were designed by people; they didn’t evolve. We need to consider whether it is credible that genes for niceness, retribution, and forgiveness could appear by mutation, successfully invade a population of other strategies, and resist being invaded by subsequent mutations. 12.4 Simulating evolution of cooperationEvolution of Cooperation is the title of the first book where Axelrod presented results from Prisoner’s Dilemma tournaments and discussed the implications for the problem of altruism. Since then, he and other researchers have explored the evolutionary dynamics of PD tournaments, that is, how the distribution of strategies changes over time in a population of PD contestants. In the rest of this chapter, I run a version of those experiments and present the results. First, we’ll need a way to encode a PD strategy as a genotype. For this experiment, I consider strategies where the agent’s choice in each round depends only on the opponent’s choice in the previous two rounds. I represent a strategy using a dictionary that maps from the opponent’s previous two choices to the agent’s next choice. Here is the class definition for these agents:
In the In this implementation, the genotype of an agent who always defects is The
Mutation works by choosing a random value in the genotype and flipping from
Now that we have agents, we need a tournament. 12.5 The TournamentThe
The
After the given number of rounds,
Inside the loop, we select two agents, invoke 12.6 The SimulationThe Here’s the
A Here’s the
This version of
My simulation includes differential survival, as in Section ??, but not differential reproduction. You can see the details in the notebook for this chapter. As one of the exercises, you will have a chance to explore the effect of differential reproduction. 12.7 ResultsSuppose we start with a population of three agents: one always cooperates, one always defects, and one plays the TFT strategy. If we run But “always defect" contains the seeds of its own destruction. If nicer strategies are driven to extinction, the defectors have no one to take advantage of. Their fitness drops, and they become vulnerable to invasion by cooperators. Based on this analysis, it is not easy to predict how the system will behave: will it find a stable equilibrium, or oscillate between various points in the genotype landscape? Let’s run the simulation and find out! I start with 100 identical agents who always defect, and run the simulation for 5000 steps:
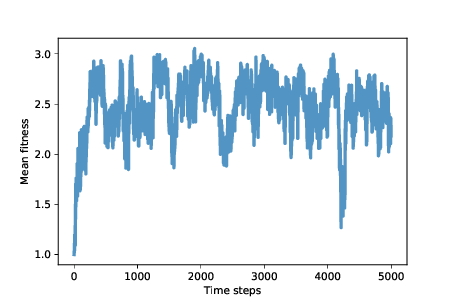
Figure ?? shows mean fitness over time (using the After about 500 time steps, mean fitness increases to nearly 3, which is what cooperators get when they face each other. However, as we suspected, this situation in unstable. Over the next 500 steps, mean fitness drops below 2, climbs back toward 3, and continues to oscillate. The rest of the simulation is highly variable, but with the exception of one big drop, mean fitness is usually between 2 and 3, with the long-term mean close to 2.5. And that’s not bad! It’s not quite a utopia of cooperation, which would average 3 points per round, but it’s a long way from the dystopia of perpetual defection. And it’s a lot better than what we might expect from the natural selection of self-interested agents. To get some insight into this level of fitness, let’s look at a few more instruments.
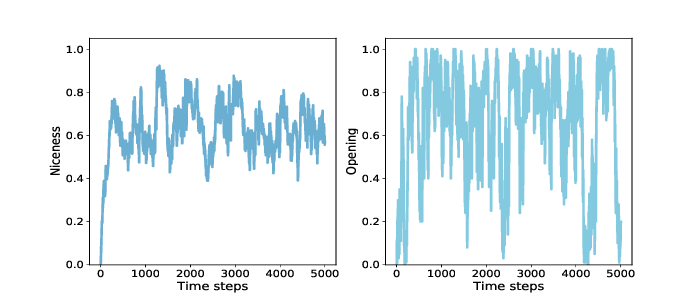
Figure ?? (left) shows the results: starting from 0, average niceness increases quickly to 0.75, then oscillates between 0.4 and 0.85, with a long-term mean near 0.65. Again, that’s a lot of niceness! Looking specifically at the opening move, we can track the fraction of agents that cooperate in the first round. Here’s the instrument:
Figure ?? (right) shows the results, which are highly variable. The fraction of agents who cooperate in the first round is often near 1, and occasionally near 0. The long-term average is close to 0.65, similar to overall niceness. These results are consistent with Axelrod’s tournaments; in general, nice strategies do well. The other characteristics Axelrod identifies in successful strategies are retaliation and forgiveness. To measure retaliation, I define this instrument:
This result provides weak support for the claim that successful strategies retaliate. But maybe it’s not necessary for all agents, or even many, to be retaliatory; if there is at least some tendency toward retaliation in the population as a whole, that might be enough to prevent high-defection strategies from gaining ground. To measure forgiveness, I define one more instrument to see whether agents might be more likely to cooperate after D-C in the previous two rounds, compared to C-D. In my simulations, there is no evidence for this particular kind of forgiveness. On the other hand, the strategies in these simulations are necessarily forgiving because they consider only the previous two rounds of history. In this context, forgetting is a kind of forgiving. 12.8 ConclusionsAxelrod’s tournaments suggest a possible resolution to the problem of altruism: maybe being nice, but not too nice, is adaptive. But the strategies in the original tournaments were designed by people, not evolution, and the distribution of strategies did not change over the course of the tournaments. So that raises a question: strategies like TFT might do well in a fixed population of human-designed strategies, but can they evolve? In other words, can they appear in a population through mutation, compete successfully with their ancestors, and resist invasion by their descendants? The simulations in this chapter suggest:
Obviously, the agents in these simulations are simple, and the Prisoner’s Dilemma is a highly abstract model of a limited range of social interactions. Nevertheless, the results in this chapter provide some insight into human nature. Maybe our inclinations toward cooperation, retaliation, and forgiveness are innate, at least in part. These characteristics are a result of how our brains are wired, which is controlled by our genes, at least in part. And maybe our genes build our brains that way because over the history of human evolution, genes for less altruistic brains were less likely to propagate. Maybe that’s why selfish genes build altruistic brains. 12.9 ExercisesThe code for this chapter is in the Jupyter notebook chap12.ipynb in the repository for this book. Open the notebook, read the code, and run the cells. You can use this notebook to work on the following exercises. My solutions are in chap12soln.ipynb. Exercise 1 The simulations in this chapter depend on conditions and parameters I chose arbitrarily. As an exercise, I encourage you to explore other conditions to see what effect they have on the results. Here are some suggestions:
Exercise 2 In my simulations, the population never converges to a state where a majority share the same, presumably optimal, genotype. There are two possible explanations for this outcome: one is that there is no optimal strategy, because whenever the population is dominated by a majority genotype, that condition creates an opportunity for a minority to invade; the other possibility is that the mutation rate is high enough to maintain a diversity of genotypes. To distinguish between these explanations, try lowering the mutation rate to see what happens. Alternatively, start with a random population and run without mutation until only one genotype survives. Or run with mutation until the system reaches something like a steady state; then turn off mutation and run until there is only one surviving genotype. What are the characteristics of the genotypes that prevail in these conditions? Exercise 3
The agents in my experiment are “reactive” in the sense that their choice during each round depends only on what the opponent did during previous rounds. Explore strategies that also take into account the agent’s past choices. These strategies can distinguish an opponent who retaliates from an opponent who defects without provocation.
|
Buy this book at Amazon.com
ContributeIf you would like to make a contribution to support my books, you can use the button below and pay with PayPal. Thank you!
Are you using one of our books in a class?We'd like to know about it. Please consider filling out this short survey.
|